(「Unicodeとインド系文字」として連載したメモです。 素材の配列などが練れていませんが、暫定的にそのまま再録しておきます。)
最初の例は ক と য (Unicode名でKAとYA)。 前半文字の母音を消して結合させる(=KYA)。 YAはC2結合的だ。KYAになってKAが「半分」になっているのに、字形上は逆にYAが「半分」になっている。 半分というか、縦の波線にまで退縮。
ちなみに日本語のひらがな「きゃ」も KYAで「き」がハーフ、「や」がフルなのに、字形上は逆に「や」がハーフになっている。

KYAは全結合(Vi)してもC1側は原形のままだ。 言い換えると、YAがC2になるC2結合は、デフォルト(全結合)が半結合で、 C2半結合を強制(J-Vi)しても、全結合と同じ字形になっている。 実はこの点は Unicode 5.0規格で明示されていて、 後半が波線のYAのときは Vi でも J-Vi でも原則として同じになること、 つまりJは不可欠ではないがあってもいいことが保障されている(RAが絡むときは例外だが、これについては後述)。 C1半結合を強制(Vi-J)することは普通にできる(現実的ではないかもしれないが)。
次の例は র RA + ক KA の RKA で、こちらはC1結合なのだが、RAが次の文字の上に付く斜めの線にまで簡略化されてしまう。 Rがこういう感じに書かれるのは、サンスクリットなどインドのほかの文字でも一般的だ。 こちらも全結合してもC2側がフルで残る。全結合といっても字形は半結合。 その点、最初のYAの例と似ているが、YAが後半の場合C1がフルで残るのに対して、 RAが前半だとC2がフルで残る。どちらがフルで残るかの前後関係は異なっている。 一応半結合で書けるが、ハーフフォームが乗る場所が手前になるだけで、字形上あまり意味がない。 このペアはC2半結合はしないので強制(J-Vi)しても無効。
こうした YAの独特さと、RAの独特さを組み合わせたのが3例目 RYA だ。 全結合(および理論上は可能なC1半結合)は問題ないが、RKAと違ってC2結合可能ペアなので、 J-Vi が有効だ。その場合、C1のRAは普通は上部の斜線に退縮してしまうのに、一転して(KYAと同様)今度はRAがフルフォームで、YAは縦の波線に退縮する。
この結果、RYAは、全結合と、C2半結合とで、同じ内容の文字なのに非常に異なった姿になる。 どちらの字形も実際に使われるため、この区別は実用上も重要だ。 「後半が波線のYAのときは Vi と J-Vi は同じ意味」という原則の例外でもある。
Unicode 4.0.1(2004年)では、このC2半結合をNJ-Viで制御していた。仕様書では:

Unicode 5.0(2006年)ではJ-Viに変わった。仕様書では:

実装上はどちらの書き方でも動作するが、何の説明もなくこの場合のZWNJがZWJに変わったので、混乱の原因になる。
テキストによる表示(フォントの違いなどで、必ずしも画像と完全に同じにはなりません。)
| C1 | C2 | Vi | Vi-J | Vi-NJ | J-Vi | NJ-Vi |
|---|---|---|---|---|---|---|
| ক | য | ক্য | ক্য | ক্য | ক্য | ক্য |
| র | ক | র্ক | র্ক | র্ক | র্ক | র্ক |
| র | য | র্য | র্য | র্য | র্য | র্য |
C2結合(後述)する文字の中でも比較的メジャーなベンガル文字。
インド系の文字はよく2文字以上が合体して合字を作る。 日本語の文字も「㌧」とか「㌦」とか普通に合体し、極端になると6身合体「㌖」というありさまだが、 インドの文字の合体も奥が深く、全結合・半結合・非結合などの区別がある。 カタカナで例えると、
「スクール」というカタカナで school を表すとする。 「スク」はそのままだとSUKU。そこで「ス」に母音が付かないSKUを表現したいと思ったとする。 (「ル」も問題だが、本題と関係ないので無視。)
1. 仮に ̣ が母音なしを表す記号(Unicode用語ではVIRAMA)だとすると、「ス̣ク」で非結合的にSKUを表現できる。記号が付いている以外「ス」も「ク」も文字自体は変形合体しないので非結合という。
2. 「ㇲクール」
のように前半の「ス」を変形することで普通の「ス」じゃないよ、と示すのがC1結合、
「スㇰール」
のように後半の「ク」を変形することで「ク」の直前の母音は消えてるよ、と示すのがC2結合。
「ㇲク」ないし「スㇰ」が全体でひとまとまりになって、片方の文字が小さくなり、
字形的には二文字が親子関係になり半分合体しているが、完全融合とはいえない。
半結合という。
3. 仮に「久」がSKUという合字(母音なしの「ス」と「ク」の完全合体)だとすると 「久ール」の「久」は「ス̣ク」の全結合。
VIRAMAが母音なしを示す記号だと書いたが、この記号が実際に目に見えるのは非結合のときだけで、 半結合・全結合のときはVIRAMAは不可視文字になる。 (不可視だからといってVIRAMAを書かないと、結合するしない以前に独立した「ス」と独立した「ク」が並んでいるだけで、 SUの母音も消滅しない。) この種の文字の組み合わせでは、フォントがそれをサポートしている限り、原則として全結合の字形が使われる。 その字形がなければ半結合、その字形もなければ非結合になる。 上記のようにZWJなどの制御文字を挿入すれば、原則と無関係に全結合(デフォルト)以外の形を強制できる。
何でもかんでも合体させるのは複雑で古臭い、という考え方もある。 現代日本語でも、ひらがな「ゟ」が「より」でカタカナ「ヿ」が「コト」だ、などというのは一般的でないだろう。 インドの文字でも、理論的に全結合が可能でも、 半結合や非結合が好まれる場合がありうる。 その場合はZWJなどを書かなくても、全結合にならない。
多くの文字は半結合のときC1結合的になる。
つまり母音を奪われる文字(「スク」の「ス」)の方がちっちゃくなって他方の文字は変形しない。
常識的な話だ。
しかし逆になる例もある。
例えば
「スㇰール」
は「ス」の方をちっちゃくするのが論理的な気もするが、
「スㇰ」
は「スク」を一まとめに速く読めという意味だよ、速く読めば真ん中の母音は脱落するよ、と考えれば、分からないでもない。
慣れてしまえば、そういう書き方でも問題ないだろう。
実際、ひらがな「にょ」NYO は、「に」がハーフ(NIのIが脱落)、「よ」がフル(YO)なのに、字形上は逆に「よ」がハーフになっている。
この合体方法をC2結合というが、Unicodeでどう表現するかの仕様が途中で変更されており、技術的におもしろい。
ベンガル文字に話を戻して。
以下の検証は フォントが Vrinda のバージョン5.9、 USP10.dll が VOLT 1.3 を使っている。前者はWindows 7 RCのISOイメージから抽出したもの、 後者は無印Vista相当だが、実際の実験は Windows XP SP3上で行っている。
二つの文字C1とC2の結合を考える。 表で最初の行の見出しは「C1とC2の間に挟まるもの」。 簡単のためVIRAMA(U+09CD BENGALI SIGN VIRAMA)をVi、 ZWJ(ゼロ幅結合制御文字)をJ、 ZWNJ(ゼロ幅非結合制御文字)をNJと略している。 3列目が全結合、4列目が半結合、5列目が非結合、最後の2列はどちらもC2結合的な半結合で、 左が新しいUnicode 5方式、 右が古いUnicode 4方式。 いずれもC1はデッド(母音なし=「スクール」の「ス」の立場)。

Viの列は C1+VIRAMA+C2 で、全結合。 Vi-Jの列は C1+VIRAMA+ZWJ+C2で、C1が「ハーフフォーム」(と便宜上呼んでおく)になった半結合。 Vi-NJの列は C1+VIRAMA+ZWNJ+C2 で、非結合。 「スク」の例えから分かるように、 全結合・半結合・非結合は書き方の問題で内容に違いはない。
ヘッダの下、最初の2行はC1結合的で、C2結合はしない。 無理に要求するとごらんのように非結合になってしまう。 それも単に非結合でなくVIRAMAの位置が少し右に寄っている。 「間違ってる組み合わせだぞ、VIRAMAを先に書けよこら」と暗示している?
3番目と4番目の2例はC2結合が可能だが、 上記と同じ方法で強制的にC1側をハーフフォームにしてC2側を全部書くようにもできる(Vi-J)。 C2側をハーフフォームにするには制御文字を逆順のJ-Viにする。 具体例として適切かは分からないが概念的に、これが2004年の「PR-37」提案だ(現在は正式規格)。 C1をまるまる普通に書いたのと並べて(この場合は真下に)C2のハーフフォームが大きめに来ている。 全結合と似ているが完全には密着・圧縮・融合しておらず、C1の方はまるまる原形をとどめている。 Unicode 4では、NJ-Viで同じことを表していた。 PR-37で書き方がNJ-ViからJ-Viに変更された。
USP10の実装では古い書き方も通用する。 XP SP2のデフォルトなど古いUSP10では、逆に古い書き方しか動作しない。 では今 Unicode 5 で Unicode 4 で定めた NJ-Vi を使っていいか。 MAY なのか、deprecated の SHOULD NOT なのか、 完全廃止で MUST NOT なのか。 規格を黙ってこっそり変更しているので、その点はあいまいだ。 Unicode 4時代に作成されたアプリやデータとの互換性のため、 少なくとも実装系側は古い書き方もサポートするべきだろう。
Vi-JとJ-Viで、つまりVIRAMAとZWJのどちらを先に書くかで、意味が変わる(特にC2結合的な場合)。 普通はVIRAMAが先、ZWJが後だが、C2結合的文字のハーフフォームを使うときはZWJを先、VIRAMAを後に書く。 仕様書を見る限りでは「PR-37対応」の根幹はこの「J-Vi」の規約だ。
テキストによる表示(フォントの違いなどで、必ずしも画像と完全に同じにはなりません。)
| C1 | C2 | Vi | Vi-J | Vi-NJ | J-Vi | NJ-Vi |
|---|---|---|---|---|---|---|
| ক | ক | ক্ক | ক্ক | ক্ক | ক্ক | ক্ক |
| গ | ন | গ্ন | গ্ন | গ্ন | গ্ন | গ্ন |
| গ | ব | গ্ব | গ্ব | গ্ব | গ্ব | গ্ব |
| হ | ব | হ্ব | হ্ব | হ্ব | হ্ব | হ্ব |
![]()
カンダタ(khanda ta = khônḍo tô コンドト)の文字は、Unicode 4.1 で追加され(U+09CE)、この結果、ベンガル文字をUnicodeで表す方法が少し変更された。C2結合問題 PR-37 より前の、[PR-30] のD案に当たる。
カンダタは考えようによってはTAのハーフ・フォームで、 以前はそうであるかのようにUnicode化されていた。 しかしその方法では、次のような問題があった。
例えばEの母音を付けるとする。 この母音は文字本体の左側の、丸かっこのような記号で表される。
下の表で、いちばん左の列は末尾にデフォルトの母音(Unicode規格ではAで表現=実際にはオの音)を持つ文字の形(母音記号なし)、2列目はその説明(略語の使い方は前回までと同じ)。3列目が母音をAからEに変えた場合の文字の形(母音記号が付く)。例えば1行目の1列目はSAの文字、3列目はその右側に丸かっこが付いたような字形でSEの文字。
KA に付ければ KE に、SKA に付ければ SKE になる。 SKA に付ける場合、完全合体している全結合形に付ける場合はもちろん、 半結合でも母音記号はその全体に付くことに注意。 結合している=一塊につながっている全体に対して母音記号が付く。 その下の TA を TE にする例も単純明快だ。
問題は次の TKA 。このTがカンダタで、疑問符が裏返ったような形をしている。 Unicode 4.0 までは TA + VIRAMA + ZWJ で、つまりTAの変種として、この字形を表していた。 表で下から3行目がこの書き方。 コード的には、あたかも TA のハーフフォームだ。 TAのフルフォームの横棒を取って、渦巻きをひっくり返して伸ばした…と思えば、字形的にもハーフフォームと言えないこともない。
そこに母音Eの記号を付けて TKE を作ろうと思ったら、常識で考えれば SKE と同様全体の左端に母音記号が付く。 USP の動作でもそうなる。 ところがここがやっかいなところで、 正書法として、それでは正しくない。この場合、 正しくは母音記号は中央に来てKにくっつく。

どうしましょう。 一つのハックとして、カンダタを表す「TA+VIRAMA+ZWJ」と後続する「KA」の間に ZWNJ を入れて「この二つの文字は字形的につながりませんよ」とユーザー側から主張することが考えられる。 表の下から2行目だ。 仕様にない独自表記だが、 試してみると USP はどうやらそれで正しく動作する。 しかし結合文字ZWJの後ろに非結合文字ZWNJを入れるのはいかにもぎこちない。
別のアプローチとして、レンダリング側がベンガル語についての知識を持ち、 「同じTでもKが後ろのときはこうで…」と自分で判断することも考えられる。 組み合わせを全部ハードコーディングしてしまうのだ。 面倒だし、スマートでないが、やってやれないことはない。 マイクロソフトの開発者は最初PR-30でこの案を推し(2004年2月)、 カンダタを新しい文字として定義することには消極的だった。
Unicode 4.1.0(2005年)で、カンダタは独立したコードポイントを与えられた。 そのため表記も、表の最後の行のように単純になった(Viramaも制御文字も不要)。 もともと歴史的・文化的にも「カンダタと普通のTは別々の文字」という考え方もあったらしい。 ただ、そうなると波線のYAも別のコードポイントでいいのでは、という話になるし、 実際、そういう意見もあるようだ。
現在のUnicode 5.0の規格書を見ると、カンダタの以前の書き方は「推奨しない」となっている。 上記のように古い書き方では問題があること自体については特に言及がないが、 [N2811] は「Unicode 4.0の方法では উৎকোচ という語が正しく書けない」と具体例を挙げている。 [N2813] では TA+Vi+J+TA+E の母音位置がおかしくなることを記述している。 上で紹介した例と同じ現象だ。 実際に旧方式でうまく書けない単語があるのだから、カンダタを独立した文字にしたのは単に「収録文字の種類を増やしました」という以上の意味があったことになる。
デッド(母音なし)のTが常にカンダ・タで表記されるわけではなく、 例えば通常のタにViramaを付けても同じ音を表す別の字形になる。 しかしカンダ・タで表記される場合は(実際の文字の形の上でも、Unicode的にも)Virama不要で、 自動的にデッドとなる。
テキストによる表示(フォントの違いなどで、必ずしも画像と完全に同じにはなりません。)
| স | SA | সে |
|---|---|---|
| ক | KA | কে |
| স্ক | SKA (Vi) | স্কে |
| স্ক | SKA (Vi+J) | স্কে |
| ত | TA | তে |
| ত্ক | TKA (Vi+J) | ত্কে |
| ত্ক | TKA (Vi+J+NJ) | ত্কে |
| ৎক | TKA (khanda ta) | ৎকে |
^ [PR-30] Constable, Peter (2004). ![]() Encoding of Bengali Khanda Ta in Unicode, Public Review Issue #30.
Encoding of Bengali Khanda Ta in Unicode, Public Review Issue #30.
^ [N2811] Sengupta, Gautam (2004). ![]() FEEDBACK ON PR-30: Encoding of Bangla Khanda Ta in Unicode, JTC1 SC2/WG2 N2811.
FEEDBACK ON PR-30: Encoding of Bangla Khanda Ta in Unicode, JTC1 SC2/WG2 N2811.
^ [N2813] Constable, Peter (2004). ![]() Review of Bengali Khanda Ta and PRI-30 Feedback, JTC1 SC2/WG2 N2813.
Review of Bengali Khanda Ta and PRI-30 Feedback, JTC1 SC2/WG2 N2813.
![]()
グルムキー文字はパンジャーブ語を書くのに使う。 パンジャーブ語は約1億の話者がいる大言語で、 インド北部、パンジャーブ州の公用語。 デリー首都圏の公用語の一つでもある。 パキスタンのパンジャーブ州(インドのパンジャーブ州と同名)でも、公用語ではないが広く使われる。ただしそちらではパンジャーブ語を書くのにグルムキー文字よりアラビア文字系の「シャームキー」を使うようだ。
現代のグルムキー文字はほかのインド系の文字と比べるとシンプルで、Unicode上の実装も整備されている。 歴史的なグルムキー文字は現代のものよりかなり複雑で、Unicode上では仕様が不十分な部分もあるし、フォントの実装も完全でない。
Wikipedia の Gurmukhī script の項には、
Virama はほとんど使われないとあるが、それは可視のViramaのことで、
Unicode規格上の形式的なViramaは現代でも普通に使われる。
例えばパンジャーブ語で「金曜日」という意味の単語シュクルヴァールの一つの書き方として
ਸ਼ੁਕ੍ਰਵਾਰ SHUKRAVAAR
があり、文字でKRAの部分がKA+VIRAMA+RAとなっている。
文字上ではこのViramaは不可視。 「金曜日」には ਸ਼ਨੀਚਰਵਾਰ など違う少し書き方もある。 この例に限らず、実際の発音は文字通りではなく母音の脱落などがある。逆に言えば、母音が脱落する場所にいちいち全部Viramaを付けない=通常Viramaは不要、となる。 Viramaが必要なのは前後の子音が発音上結合するときではなく、 前後の文字が字形上、結合するとき。 その意味でグルムキーのViramaは、次の文字がC2結合することを表す制御文字であり、 ほかのインド諸言語との統一のためViramaを使っているが、 Unicode的にはZWJのようなものだ。 ユーザーの素朴な意識としてはViramaでもZWJでもなく、単に「小さい文字」というところだろうか。
現代のグルムキー文字では、 上記「金曜日」の例で現れた-RAを含めて、 子音群の結合表記は4種類しかない。
(画像による表示)

(テキストによる表示)
| C1 C2 | C1 Vi C2 | SP J Vi C2 | |
|---|---|---|---|
| MUHA, MHA, -HA | ਮਹ | ਮ੍ਹ | ੍ਹ |
| PARA, PRA, -RA | ਪਰ | ਪ੍ਰ | ੍ਰ |
| DAVA, DVA, -VA | ਦਵ | ਦ੍ਵ | ੍ਵ |
| DAYA, DYA, -YA | ਦਯ | ਦ੍ਯ | ੍ਯ |
C1側はこれ以外の文字も来るが、C2半結合(=結合してもC1側の字形は変わらない)なので字形の上では4種類だけだ(しかもVAの用例はまれ)。スペース+ZWJ+VIRAMA+C2で、この4種類のC2結合形を独立表示している(PR-37仕様)。 点線の円のようなものが見えるのは「そこに何かが来る」というプレースホルダーで、実際の文字の一部ではない。同じC2結合でも、HA/RA/VAはC1の下に付き、YAはC1の右に付く。 実際に結合させるときは間にViramaを入れるだけで十分で、ZWJ+Viramaとする必要はない(ZWJを付けても正しく表示されるが、ZWJを付けてもいいことは規格上、明示的には保障されていない)。
歴史的にはこれ以外の結合もあった。 シク教の聖典「グル・グラント・サーヒブ」(スリ・グル・グーラント・サーヒブ、以下SGGSと略)では、 CA/TTA/TA/NA もC2結合で下に付く例が若干ある。 これら歴史的表記は少し前のUnicode 4.0に含まれておらず、Saabフォントや、 Arial Unicode MS では対応していないが、 AnmolUniBani、Akaash、FreeIdgSerif、Raaviなどでは対応している。 このほか、SGGSにはYAKASHとUDAATという記号があり、 ごく最近Unicode 5.1で対応した(後述)。
SGGSでは例がないものの、 古くはGA/TTHA/THA/DA の4種類もC2結合して下に来た。[Thind] サポート状況は上記と同様。
さらにUnicode 5.0の仕様書は、YAが下付きに、 THAとMAが右付きにできたとする。YAは同じコードで右付きになるので「下付きのYA」は技術的に問題がある。 4.1.0規格では、HALF YAとPARI YAとしてViramaの順序でアドホックに区別するとしたが、 両方C2結合なので、うまくない。 (PR-37によりC2結合の独立形はVirama+C2の順序と想定される。) 5.0.0では削除されている。 同様に、THAは半結合では下付きになるので「右付きのTHA」は問題がある。 「右付きのMA」にはそうしたあいまいさはないが、上記各フォントのいずれもサポートしていない。 古文書ではまれにSAとRAのC1半結合の例があるらしいが(RAはいわゆるRephになる)、これもフォントでは未実装。
逆にUnicode仕様書には記載されていないが、AnmolUniBaniが独自サポートしている下付きがある。 JA/DDA/NNA/DHA/LAの5種類は公式サイトで紹介されているが、 実際に試すとKAも下付きにできる。
U+0A75 GURMUKHI SIGN YAKASH は y の音を表すフック状の小さな文字で、 SGGSでは268回使われている。[N3073] 母音が内在せず、最初からデッドだ。
U+0A51 GURMUKHI SIGN UDAAT は古文書で高いピッチのアクセントを表すアクセント記号とされる。 字形自体は HA から派生し、歴史的にはサンスクリットの U+0951 DEVANAGARI STRESS SIGN UDATTA と関係ある。 SGGSでは1188回使われている。[N3021] SGGSの場合、 ハーフフォームの下付きHAと区別なく用いられているようだが、Udaatの方が圧倒的に用例が多い。
Unicodeに追加される以前にも、YYA や HHA を使ってこれらを表現する実装例がある。 AnmolUni、AnmolUniBani、Akaashなどで用いられているハックだ。
次の表は、AkaashフォントがUnicode 4時代のコードポイントだけを使ってYakashとUddatを独自実装していた様子を示す。Unicode 5.1で標準化された表記法、および、独自拡張を持たないRaaviでの出力例を参考として添えてある。 RaaviフォントはYakashの付く場所が少し違うが、これは単に文字デザインの違いだ。
(画像による表示)

(テキストによる表示)
| Akaash | Raavi | |
|---|---|---|
| SA+YA | ਸਯ | ਸਯ |
| SYA (Vi) | ਸ੍ਯ | ਸ੍ਯ |
| SYYA (Vi,Vi) | ਸ੍ਯ੍ਯ | ਸ੍ਯ੍ਯ |
| SYA (Yakash) | ਸੵ | ਸੵ |
| SA+HA | ਸਹ | ਸਹ |
| SHA (Vi) | ਸ੍ਹ | ਸ੍ਹ |
| SHHA (Vi,Vi) | ਸ੍ਹ੍ਹ | ਸ੍ਹ੍ਹ |
| SA+UDDAT | ਸੑ | ਸੑ |
注: 古いバージョンのRaaviフォントではSHHAが違った表示になるが、 この組み合わせはもともとハックなので重要な問題ではない。
^ [N3021] Sidhu, Sukhjinder (2005). ![]() Proposed Changes to Gurmukhi 3, JTC1 SC2/WG2 N3021.
Proposed Changes to Gurmukhi 3, JTC1 SC2/WG2 N3021.
^ [N3073] Sidhu, Sukhjinder (2006). ![]() Gurmukhi Sign Yakash, JTC1 SC2/WG2 N3073.
Gurmukhi Sign Yakash, JTC1 SC2/WG2 N3073.
^ [Thind] Thind, Kulbir S (2008). Unicode Gurmukhi Fonts and Information, Information Regrading Gurmukhi Unicode Fonts, and Interesting Text Trivia about Sri Guru Granth Sahib Text, GurbaniFiles.org.
![]()
オリヤー(オディアー)文字はオリヤー語の表記に用いられる文字。 オリヤー語はインドのオリッサ州で使われる言語で、インドの公用語の一つでもある。 オリッサ州はインド東部でベンガル湾に面し、人口3680万(2001年)。 古くから文化が栄え、コーナーラクにある太陽神スーリヤの寺院はユネスコ世界遺産だ。

日本語で使われることのあるオリヤー語系の単語として、お菓子の「ラスグッラ」がある(オリヤー語ラサゴーラー rasagoḷā に当たるヒンディー語)。 インド全国でポピュラーなミルクと粉を混ぜたような甘い団子だが、起源はオリッサ州。 本場では単なるミルクではなく「チェーナ」という水牛の乳の生チーズ、そしてパスタと同じセモリナの粉を使うらしい。

オリヤー文字のUnicode表記には、いろいろと微妙な点がある。 例えば上で「オリッサ」という語に含まれるRRAをDDA+NUKTAに分解してエンコードしたが、これがNFCにあたり、W3Cご推奨ということになる。 ところが同じNFCでは、デーバナーガリーのRRAは1コードポイントに合成される。 このようになるのは、Unicode規格のCompositionExclusions-5.1.0.txtで、0B5C ORIYA LETTER RRAが合成から除外されている一方、 デーバナーガリーのRRAは除外されていないため。
インド系文字で一般的に言う(例えばデーバナーガリー文字の)YA/JAとオリヤー文字のYA/JAは文字的に対応しているが、
発音的には対応していない。
現代オリヤー語では発音上は両方JAだ。
同時に、本当にYAと読む「変種のYA」があって、UnicodeではYYAと呼ばれる。
U+0B2F [ ଯ ] ORIYA LETTER YA
U+0B5F [ ୟ ] ORIYA LETTER YYA
ラテン文字で転写するときは、前者の子音が y 後者の子音が ỵ だが、 この y は [dʒ] で ỵ が [j] になる。
オリヤー文字にもベンガル文字の Ya-phalaa に相当するものがある。 つまり、二つの文字C1とC2が結合形を作る場合、C2がYYAだと、その部分はロシア文字の ч のような形になってベース文字の右側にC2半結合する。 KA+YYAでKYYAを作る例で考えると、
| C1 | C2 | Vi | Vi-J | Vi-NJ | J-Vi | NJ-Vi |
|---|---|---|---|---|---|---|
| କ | ୟ | କ୍ୟ | କ୍ୟ | କ୍ୟ | କ୍ୟ | କ୍ୟ |
全結合形(Vi)の右側の ч のような部分に注目。 ベンガル文字の同様の例ではZWJをVIRAMAに前置しても良いという特別ルールがあったが(そしてPR-37以前にはZWJでなくZWNJを使っていたが)、 オリヤー文字でも(明文規定はないが実装上)それらは成立している。ベンガル文字のKA+YA=KYAの例と比較しよう。
| C1 | C2 | Vi | Vi-J | Vi-NJ | J-Vi | NJ-Vi |
|---|---|---|---|---|---|---|
| ক | য | ক্য | ক্য | ক্য | ক্য | ক্য |
C1結合が基本のベンガル文字ではVi-Jが意味を持ったが、C2結合が基本のオリヤー文字ではVi-Jは無意味で非結合と同じ扱いになる。
以下、ここでは、この ч のような要素を(右付きの)パラーと呼ぶことにする。
Unicode 5.1現在、ベンガル文字と同じで、パラー記号は独自のコードポイントを持たず、YYAの表示形の一種という扱いだ。
ベンガル文字のYAは(大ざっぱに言えば)波線のような部分を持っているのでベンガル文字の ya-phalaa の形はハーフフォームと納得がいくが、
オリヤー文字のYYAパラーは、YYAと比較しても何でこんな字形になるのかと感じる。
歴史的には恐らくベンガル文字と同じで、オリヤー文字のYYAパラーも、YYAでなくYAから生まれたのではないか。
YAの字形を(大ざっぱに言って)右上から左下への対角線で切断して右半分を取れば、パラー記号が得られるので…。
![]()
実際、utkal フォントの実装では、ZWJ+VIRAMA+YAでパラーが出る。 つまりベンガル文字と同じにYAパラー(YYAパラーでなく)を使う。 そしてZWJ+VIRAMA+YYAだと、YAパラー+NUKTAになる。 初期のUnicode規格では、YYAをYA+NUKTAとみなしていたらしい。 「オリヤー語話者にYYAをYA+NUKTAだと考える人は一人もいない」と一蹴されている。[Hellingman] 現在ではこのフォントは例外的で、ほかのフォント(RaghuOriya、Kalinga、Arial Unicode MS、Code2000)は右付きパラーをYYAから作る。 仮に上の想像が合っていて歴史的にパラーはYAから生まれたのだとしても、現在のオリヤー語の発音ではYAはもはやパラーが示す [y] の音ではなく、 YYAがパラーと同じ子音になる(そしてパラーはYYAの結合形として表現される)。
オリヤー文字でも、RAはC1位置で結合すると上付き(小さい「く」のような形)に、C2位置で結合すると下付きに(右に短い縦線が付いた水平線)になる。 後者はRAパラーと呼ばれることもあるようだ。 RYYAは、ベンガル文字のRYAと平行的な二重性を持つ。ベンガル文字と違うのは、

テキストによる表示。
| C1 | C2 | Vi | Vi-J | Vi-NJ | J-Vi | NJ-Vi |
|---|---|---|---|---|---|---|
| କ | ୟ | କ୍ୟ | କ୍ୟ | କ୍ୟ | କ୍ୟ | କ୍ୟ |
| ର | କ | ର୍କ | ର୍କ | ର୍କ | ର୍କ | ର୍କ |
| ର | ୟ | ର୍ୟ | ର୍ୟ | ର୍ୟ | ର୍ୟ | ର୍ୟ |
| ୟ | ର | ୟ୍ର | ୟ୍ର | ୟ୍ର | ୟ୍ର | ୟ୍ର |
| କ | ତ | କ୍ତ | କ୍ତ | କ୍ତ | କ୍ତ | କ୍ତ |
オリヤー語では本来Vの音がなく、一般には外来語などのV音はBAの文字で表される。
学術などで特にVを区別したい場合には、まれに特殊文字が用いられる(Unicodeの例示字形ではBAに点を付けたもの)。
U+0B2C [ ବ ] ORIYA LETTER BA
U+0B35 [ ଵ ] ORIYA LETTER VA
U+0B71 [ ୱ ] ORIYA LETTER WA
Wの音は存在している。 ただし、WAは外来語用の特殊文字とされ、オリヤー語本来の(C2位置の)Wの音は、BAで表すものとされる。 つまりC2位置のBAは [wa] を表すことが多い(文字通りに [ba] を表すこともある)。
オリッサ州の州都の名前 Bhubaneśbar は、 オリヤー文字で ଭୁବନେଶ୍ବର だが、BAの独立形と、SHA+BAの結合形を両方含んでいる。 前者のBは普通に [b] を表す。 後者のBは、子音結合後半なので [w] または [b] を表す。 よって「ブバネースワル」または「ブバネースバル」のような音になるだろう。 2009年8月現在、ウィキペディア日本語版はオリッサ州の州都を「ブヴァネーシュヴァル」と表記しているが、 オリヤー語には原則「ヴァ」の音はないので、現地音主義の立場からすれば不適切だ。 File:Bhubaneshwar.ogg はインド人による実際の発音。 インドといっても言語が多いのでオリヤー語ネイティブが吹き込んだのかは分からない。

ブバネースワルのルチカ高校にて。 ディガント・ブヤン君、あだ名はダッブ。
BAが後半となる結合形は、C1がRAのとき、つまり全体としてRBAのときは、上付きRAの規則が優先し、BAを [wa] と読まないようだ(未確認)。
ର୍ବ RBA [rba]
C1がMAのとき、つまり全体としてMBAのときは、下付きのパラー記号(のようなもの)として表記される。
この場合もBAを [wa] と読まないようだ(Unicode規格書で例示)。
ମ୍ବ MBA [mba]
下付きのパラー記号は、右付きのパラーと違って、BAの文字の省略形と思われる。
![]()
そのほかの一般の場合はどうか。 Unicode規格書によれば原則 [wa] と読むらしい。 字形的には、Kalingaフォントの現在の実装では、小さいBAが下付きになる。 Unicode規格外だが、このフォントはC2位置のWAで下付きパラーを表している(WAパラー)。 Unicode規格では、例えばKBAの例示字体で下付きパラーが用いられ、フォントの実装と必ずしも一致しない。
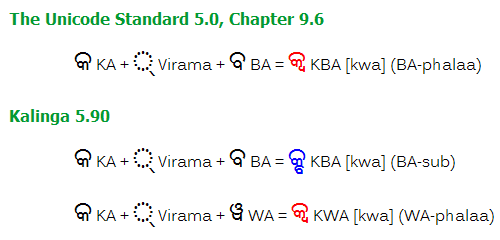
インドの [TDIL] でも、Unicode標準ではなく、Kalingaと同じ方式を使っている。 Unicodeの規格を書いたというMichael Everson本人は Oriya: mba / mwa ? の中で、 Unicodeの方式が正しいと主張しているが、 参照しているソースは「オリヤー語30日入門」だけで、信頼度は不明。
実際の表示はフォントによっても異なるだろう。
表示テスト用のテキスト。
[kwa] କ୍ବ KBA: କ୍ୱ KWA —
[ɡwa] ଗ୍ବ GBA: ଗ୍ୱ GWA —
[ɡʱwa] ଘ୍ବ GHBA: ଘ୍ୱ GHWA
[tʃʰwa] ଛ୍ବ CHBA: ଛ୍ୱ CHWA
[ʈwa] ଟ୍ବ TTBA: ଟ୍ୱ TTWA —
[ɖwa] ଡ୍ବ DDBA: ଡ୍ୱ DDWA — [ɳwa] ଣ୍ବ NNBA: ଣ୍ୱ NNWA
[twa] ତ୍ବ TBA: ତ୍ୱ TWA —
[tʰwa] ଥ୍ବ THBA: ଥ୍ୱ THWA —
[dwa] ଦ୍ବ DBA: ଦ୍ୱ DWA —
[dʱwa] ଧ୍ବ DHBA: ଧ୍ୱ DHWA
[nwa] ନ୍ବ NBA: ନ୍ୱ NWA
[lwa] ଲ୍ବ LBA: ଲ୍ୱ LWA
[swa]* ଶ୍ବ SHBA: ଶ୍ୱ SHWA —
[swa]* ସ୍ବ SBA: ସ୍ୱ SWA
[ɦwa] ହ୍ବ HBA: ହ୍ୱ HWA
[swa]* については、 二重子音の前半 s と後半 w の両方について疑義がある。 File:Oriya Consonants.gif によると ଶ と ସ は文字は区別するが発音は同じらしい。 Oriya languageでもオリヤー語のSの発音では [s] があるだけで [ʃ] や [ʂ] はない。 つまり前半は両方 [s] と考えられる。 一方、後半部分の読み方だが、 SHBAについては、[sba] と読むという記述もある(あまりあてにならないが)。 そうだとすると SBA も [sba] なのかもしれない。単語や地域や話者によっても読み方が違うのかもしれない。
WAの文字は、形の上ではO(オー)の母音字+下付きパラーだが、 Unicode規格ではこれを独立した文字としてエンコードしている。 VAよりさらに特殊文字扱いで、オリヤー語ブロックの末尾におまけのように置かれている。
[TDIL] に基づく。
ଶୁଣିବେ śuṇibe [suɳibeː] こんにちは
ଧନ୍ୟବାଦ dhanybād [dʱanjbaːd] ありがとう
ସୁବିଦାୟ subidāy [subidaːj] さようなら
")
Stone, Anthony P. (1997–2002). Inter-Script Identity, Transliteration Pages.
^ [Hellingman] Hellingman, Jeroen (1998). Indian scripts and Unicode, ldc.upenn.edu.
a b
[TDIL] Department of Information Technology (2002).
![]() Language Technology Flash, April 2002,
Ministry of Communications & Information Technology, India.
Language Technology Flash, April 2002,
Ministry of Communications & Information Technology, India.
Ishida, Richard (2003). introduction to indic scripts, people.w3.org.
Constable, Peter (2003). Oriya: mba / mwa ?, The Mail Archive, unicode.
hrpansari at vsnl.net (2006). Oriya conjucts with 'ya' and 'va' and 'wa', Oriya-group.
Mohanty, Rajat Kumar (2006). Re: Oriya 'ya' and 'ba' and 'wa', Oriya-group.
Wikipedia: Oriya language, Oriya script, Wikimedia Foundation, Inc.
AncientScripts.com: Ancient Scripts: Kalinga, Lawrence Lo.
![]()

巨大なバナナの葉に乗ったチェッティナード料理(タミルナードゥ州)
CC-BY-SA: By yashima
タミル文字は主にタミル語を文字で書くのに使われる。 タミル語は2001年の統計で約6500万人の話者がおり、世界の三つの国(インド、スリランカ、シンガポール)で公用語になっている国際的な言語。 「カレー」という日本語もタミル語起源だ。
話者のうち6100万人はインドの住民で、インド最南端のタミルナードゥ州(人口6200万)に集中している。

スリランカでも、人口の約18%(300万人)はタミル系の原住民または移民で、シンハラ語とともにタミル語は公用語となっている。 古く(恐らく紀元前)から主に北部・東部に住んでいるスリランカン・タミルが約200万人(人口の13%)いて、 ジャフナ・タミルなどのタミル語の方言を話す。 近代に農園労働者などとしてインドから送られたインド人の子孫インディアン・タミルは、合計90万人程度で、 スリランカ中央部に多い。

インディアン・タミルの茶園労働者(スリランカ)
CC-BY: By Trengarasu
マレーシアにも話者が多い。 公用語ではないが人口の約8%(200万人)がインド系住民で、主にタミル人。
シンガポールでは人口の約9%(40万人)がインド系住民で、その半分以上はタミル人。 シンガポールのタミル人は、スリランカやマレーシアのタミル人と比べて数は少ないが人口に占める割合はかなり大きく、 タミル語は、マレー語・中国語(北京官話)・英語とともにシンガポールの四つの公用語の一つとなっている。
カナダにも約20万人のタミル人の移民がいる。

スリランカン・タミルの移民たち(カナダ)
CC-BY: By Taprobanus
タミル文字は、インドやスリランカでかなりの数の(文献で確認できるだけでも約10種類の)マイノリティー言語の表記にも使われる。
タミル文字は、紛らわしい部分も少しあるが、概して難しくない。 ほかのインドの文字と比べると、子音字のややこしい合体がほとんどない。 母音が付かない子音字は、原則として常に可視 virama で非結合的に書く。 その代わり母音記号がサンスクリットなどよりほんのちょっと難しめ。 ただ字形が紛らわしいだけで、理解が難しい現象はない。 難しい部分があるとしたら、文字より発音だろう。 文字の上ではRに似た音が3種類、Lに似た音が2種類(アルファベットに転写するときはRが2種類、Lが3種類)あって、 一見手ごわそうだ。
実際の口語ではそんなに細かく区別していないようだし、RやLが多種類あるのは素朴に考えるほどややこしい問題ではない。 英語の little も l を2種類含んでいる。 一個目の l はハッキリ l だが、二個目は w に似た音になる(「リトゥ」のように聞こえる)。 また red の r と better の tt(速く読むとき)は違った種類の r の音だ。 …というわけで、発音の複雑さは英語と同じくらいで、 だから簡単ということにはならないが、 平均的な読者にとって、たぶんアラビア語や中国語よりは取っつきやすい。
Unicodeの符号化が本題なので語学的な面には深入りはしないが、 興味があるならオンラインのタミル語ビデオ教材が無料で簡単に利用できる。
複雑さの少ない文字体系だからUnicodeの実装も問題が少ないか…というと、残念ながら、そうではない。 むしろ単純さが原因で、この問題が起きた。
Unicode.orgには、Indic Scripts and Languages(インドの文字と言語)というFAQがあるが、それとは別に、わざわざ独立してTamil Language and Script(タミルの言語と文字)というFAQがある。タミル文字に関して疑問や問題点が多い、ということを暗示している。 さらにUnicode Technical Notes(Unicode技術ノート)は2009年8月現在30個の文書から成りさまざまな技術的問題を扱っているが、30個中4個がタミル文字の符号化に関係している。
何をそんなにもめているのか。
タミル文字は、ひらがなのような純粋な音節文字として理解することも可能だ。 50音表よりは少し文字数が多く約300種類になるが、漢字などと比べれば非常にわずかな数だ。 仮にこの約300種類の文字にコードポイントを与えれば、タミル文字の扱いはシンプルになる。 タミルナードゥ州の地方政府なども、それを望んでいるようだ。
現実には、Unicodeのタミル文字は、 デーバナーガリーをはじめとするインドの一般的な文字と同様、アブギダとしてエンコードされている。 文字単体では必ずデフォルト母音を伴い(例えばTA)、デフォルト母音以外の母音を付けたいとき(例えばTE)には文字単体+母音記号、 母音を全く付けたくないとき(例えばT)には文字単体+母音キャンセル記号(インド文字に関する一般用語ではvirama)。 簡単に言えば、ひらがなを1文字ずつ符号化する代わりに、AIUEOの符号とKSTNH…の符号だけ定めておいて、 K+Aというシークエンスは文字「か」を表し、K+Iというシークエンスは文字「き」を表し…というふうに、ある意味、遠回しに — 別の意味ではコードポイントの数を節約して合理的に — 符号化している。
歴史的にはほかのインドの文字と同系で実際にアブギダなので、ローマ字とひらがなの例えほどにはかけ離れておらず、 例えば上の例えでいうと例えば「き」の文字とK単体の文字は関係のある字形になる。
Unicodeがタミル語を現在のようにエンコードしているのは、 従来の文字コードであるISCII(インドの8ビット文字体系)との互換性からも、 理論的・歴史的にタミル文字がデーバナーガリーなどと同系であることからも、 無難な線だろう。 さかのぼって、ISCIIがタミル文字をアブギダとして扱っているのも、8ビットではどっちにしても256種類しか区点がないので、 多バイト文字にしない限り300種類は入り切らず、処理の簡単化の意味からも、インドのほかの文字との処理の統一からも、仕方なかっただろう。 一方、16ビット×17面(=約111万コードポイント)もあるUnicodeでは、理論的には、 タミル文字を音節文字として符号化することは極めて容易だ。 もしタミル文字の専門家が熟慮を重ねて符号化方法を選んでいたら、実際にそうなっていた可能性もある。 上記のタミル語関連の技術ノート4種のうち3つは、そのような音節文字的符号化(現地ではTSCII、TAB、TAMの三種類がある)と、 Unicodeのアブギダ的符号化の変換を扱ったものだ。 音節文字的符号化の方は8ビットでやりくりするため可変長の多バイト文字となっており、 Unicodeへの変換は自明ではない。
Shift_JISからUnicodeの変換も自明ではないが、少なくとも両者の間で文字は一対一に対応している。 Shift_JISの何番がUnicodeの何番、というふうに明確に指定できる。 これに対して、TABなどの現地規格とUnicodeは枠組みそのものが異なり、 比喩的に、例えば前者では「ミ」という1文字と考えられるものが、Unicode表現は「マ」+「イの母音記号」という2要素に分解される。 例えばUnicodeベースのメモ帳で「ミ」をタイプしてから間違えたと思って [BackSpace] を押したとき「ミ」1文字を削除したつもりがなぜかそこに「マ」が現れる(実際には「マ」+「イの母音記号」の後半を削除した)…というふうに、この符号化の仕組みはエンドユーザーの操作性にも関係する。
そうしたことから「Unicode方式は直観的に分かりにくい、 各文字を母音と子音に分けるのでファイルサイズが約2倍になって無駄も多い、 タミル語を読み書きできない欧米人が勝手に決めた変な方法だ」…などの不満が一部で生じてきたのだろう。 文字は言語と(従って思考・精神と)密接に関連しているため、 ちょっとした不備でも大きな抵抗感につながることがある。
ほかのインド系の文字は子音の連続を複雑な文字の合体で表現するため、音節文字として扱うことは考えにくい。 タミル文字はわずかの例外を除き非結合的なため、全結合や半結合といった文字の形の複雑な変化を考えないでいい。 だからこそ子音と母音に分けず直接グリフを考える理解が容易で、そこから異論が生じた。
Unicode.orgはFAQでどのような説明をしているか。
FAQ第一問が「Unicode規格のタミル文字符号化はどのように決められたのですか?」で、 回答は「ISCII (1988)ベースです。ISCIIは、8ビット文字コードという制約の中で、さまざまな専門家が努力を結集して生まれました」というもの。 要するに現在のUnicodeのタミル文字の制約はISCIIのせいだ、という(悪く言えば)責任転嫁。 よく読むと、専門家の努力の結集として称揚されているのはISCIIで、Unicode自体ではない。 末尾に「Unicodeのタミル文字規格は国際標準のISO/IEC 10646 とも共通です」と当たり前のことが書いてあるが、 国際的に認められていることをわざわざ断るあたり、 タミル語圏でのUnicodeに対する評価はあまり芳しくないようだ。
FAQは「タミル文字の符号化に論争はありますか?」から本題に入り、 「そうはいってもタミル語圏の人がそれで満足するのなら符号化を改訂したらいいのでは?」で問題の核心に至る。 回答は予想通り、符号化の安定性・過去の実装との互換性維持のため無理…というもの。 この問いへの回答は微妙な部分を含んでいる。 Unicodeは多言語レベルで見て符号化を単純化・効率化しており、このアプローチには大きなメリットがあって、 もし各言語ごとに専門の言語学者チームがついて規格を決定していたら、このメリットは失われただろう…というのだ。 Unicodeは言語の専門家が慎重に設計したものではないこと、 少なくともタミル文字の符号化はタミル語の専門家がやったわけではないことを、暗に認めている。 「時間と効率の関係でタミル語ど素人の私たちが手早く規格を決めてしまいましたが、これも大義のため。ご理解ご協力を…」ということだ。 FAQ第一問でも、ISCIIと違いUnicodeはインドの言語の専門家の協力をあまり得ていないことをほのめかしていた。
CJK統合でも、中国・日本・韓国で使われている同じ漢字の異字体は一括して扱おう、その方が単純になってすっきりして効率がいい…と考えたのだろうが、 このせいで、同じコードポイントでも言語によって字体を変える必要が生じてしまい、かえってややこしいことになった。 タミル文字の場合も、結論から言えば必ずしも最適の実装ではなかったようだが、 「短期間で世界中の文字体系を含めるにはある程度の妥協も必要」というUnicode.orgの趣旨も、その通りだろう。
Unicodeコンソーシアムは、決して弁解のFAQだけでお茶を濁し、問題を黙殺しているわけではない。 できる限りの最大の対応として Unicode 5.1 では Tamil Named Character Sequences を追加した。
比喩的に、「か」をK+Aで「き」をK+Iで…という符号化方法そのものは変えられないが、 K+Aというシークエンスを「ひらがな・か」、K+Iというシークエンスを「ひらがな・き」…と名付けることは可能だ。 「ひらがな・か」「ひらがな・き」…をUnicodeの2コードポイントとして一種の可変長エンコーディングを行った解釈すれば、 音節単位でタミル文字をエンコーディングすべき、というタミルナードゥ政府の要求に少なくとも半分は応じたことになる。 特にユーザー定義文字の領域(PUA)を利用して、インターフェイス・レベルでは完全に音節文字として、 保存などのときだけ内部的にUnicodeのシークエンスと関連づける、というのは実現可能だろう。
タミル語の初歩が学べるオンラインのビデオ教材 Tamil Language In Context - Unit 1 のうち、最初の2課(レッスン1と2)に対応したチート・シートです。ビデオのURLは、
http://media.sas.upenn.edu/larrc/tamil/year1/unit1lesson1.mov
http://media.sas.upenn.edu/larrc/tamil/year1/unit1lesson2.mov
テキスト、ビデオを見るとき参考にしてください。
தமிழ் Tamiḻ [t̪amiɻ] タミル
புள்ளி puḷḷi [puɭːi] 点 プリ
一般には「点」「ドット」のこと、タミル文字の表記を表す用語としては Virama のこと。(※この単語はタミル文字の話でよく出るというだけで、ビデオとは関係ありません。)
வணக்கம் vaṇakkam [ʋaɳakːam] こんにちは ワナカム(ビデオでは、立てた手のひらを前で合わせて挨拶している。必ずしもていねいに手を合わせないで、少し手を動かすだけの簡略なしぐさの場合も)
என் eṉ [en] 私の エン(イェン)
பெயர் [pejaɾ] 名前 ピェル
நீங்கள் nīṅgaḷ [niːŋaɭ] あなた様 ニンガル உங்கள் uṅgaḷ [uŋɡaɭ] あなた様の ウンガル
சொந்த ஊர் conta ūr (cont'ūr) [son̪d̪uːɾ] 出身の地、故郷の土地 ソンドゥール
எது edu [ed̪u] (物について)何? イェドゥ
இவர் ivar [iʋaɾ] イワル ここにいる彼(近距離・敬語)
யார் yār [jaːɾ] ヤール 誰
ஆமாம் āmām [amaː] アマー はい (口語では最後の-mは読まない) இல்லை illay [ilːaj] イラ いいえ、~でない ஓகோ ōgō [oːgoː] オーゴ おお、わあ、オーケー オーの母音記号は両側に付く。
புத்தகம் puttagam [put̪ːaɡam] プッタガム 本
அண்ணன் aṇṇa [aɳɳan] アナン 兄さん
இவர்கள் ivarkaḷ [iʋaɾgaɭ] イウルガ(ル) この婦人(近距離・敬称)
என்ன eṉṉa [enːa] エナ 何?
என்னுடைய eṉṉuṭaiya [enːuɖʌjj, enːuɽʌjj] エヌダィ、エヌラィ = என் 私の
அப்படியா appaṭiyā [apːaɽija] アッパリヤ そうですか
அப்போ appō [apːoː] アッポー それでは、そのとき
தம்பி ṭampi [ʈambi] タムビ 弟
அவன் avaṉ [aʋã] アヮ (その場にいない)彼、あの男(遠距離・常体)
ஒரு or [oɾ] オル 一つの
நான் nāṉ [n̪aːn] ナン 私
ஆசிரியர் āciriyar [aːʃiɾijaɾ] アーシリヤル 先生
மாணவி māṇvi [maːɳʋi] マーンウィ 生徒
ரொம்ப rompa [ɾomba] ロンバ 非常に
மகிழ்ச்சி makiḻcci [maɡiɻtʃːi] マギィッチ うれしい

タミル語でペルウダイヤール・コーウィル、日本ではヒンドゥー語ふうに
ブリハディーシュワラと呼ばれる世界遺産の巨大寺院(タミルナードゥ州)
タミル語のオンライン辞書。 ウィキペディア「タミル語」、 ウィキペディア「タミル文字」。 そのほかの資料、ウィキブックス、辞書
この記事にはパブリック・ドメインでない画像が含まれています。 利用の条件は次の通りです。
本文とそれ以外の画像はパブリック・ドメインです。
Unicode 5.1.0 で導入された Malayalam chillu のうち、 ディグラフ版 nṯ + two-part vowel のエンコーディングには疑問がある。 以下、前半で問題を端的に述べ、後半で一般向けに解説する。
Unicode 5.2の規格書第9章が数日前やっとオンライン(PDF)で読めるようになった。 Unicode 5.0より後で追加されたchillu関係で、9.9に問題が多いようだ。 まずTable 9-27での2行目で、D0EとなるべきものがD2Eとミスタイプされている。 これは単なる誤植だろう。
疑問なのがTable 9-30。左右からなる母音記号 U+0D4B [ ോ ] MALAYALAM VOWEL SIGN OO を、 U+0D47 [ േ ] MALAYALAM VOWEL SIGN EE と U+0D3E [ ാ ] MALAYALAM VOWEL SIGN AA に分解して書いている。 このような分解が許されるのは規格書290ページ以下のタミル語のところで明記されているが、 分解しない方が普通で望ましいこともそこに書いてある。 しかも許されている分解はNFD方式(母音記号1個を連続する母音記号2個に分解)であり、 下記第一例のような「表示位置に論理位置が引きずられた」分解は規格として明示的には許されていない。 േ が「内部的」にどの位置に来るか、リガチュール版とディグラフ版で差が出ることを強調したかったのだろうが、 それは文章で注記するべきことで、規格書の例示にはかなり疑問がある。 さらに最後の例の 0D7A は、0D7E の誤植だろう。 どうも国際規格の品質としては理想的とは言いがたい。 リガチュールの nṯa で chillu-n のうしろに virāma を書くところもすっきりしないが(virāmaは母音を消すことを表す記号だが、消すも消さないもchilluはもともと母音がない)、それはそういう仕様なので仕方ない。
実はこのテーブルの内容はUnicode 5.1の段階でHTMLで読めたのだが、 内部表現のバイナリ(コード番号)までは注意していなかった。 PDFになってからよくよく見て上記のことに気づいた。 もう一つの誤植は5.2の規格書が初出と思われる。
以下「論理位置」と「表示位置」という言葉を使う。 論理位置とは文字コードの内部的な順序、 表示位置とは実際に文字を表示するときの順序という意味。
インドの文字では「母音だけ」ではない音節、例えば ka とか ki を表すとき、 「子音文字+母音記号」という表現を使う。ただしデフォルトの母音というのがあって、母音がデフォルトのときは母音記号は付かない。 文字でどう書くかと実際にどう発音するかは別問題だが、ここではデフォルト母音=「aのこと」と考えて問題ない。 要するに、インドの文字で「子音を表す文字」は、実は純粋な「子音」ではなく「子音+a」を表している。 例えば、サンスクリットで k の子音は क という文字で表すが、この文字自体はそのままだと ka と読む。 Unicodeの規格を読むと「DEVANAGARI LETTER KA」のように実際にKAという文字名になっている。
日本語のひらがなの感覚で考えると、KAの文字があればKIの文字やKUの文字もありそうだ。 あることはあるのだが、 Unicode規格を見ても「DEVANAGARI LETTER KI」とか「DEVANAGARI LETTER KU」という項目はない。 ひらがなと少し違って、KIは「KA+母音記号I」、KUは「KA+母音記号U」というふうに、KAの文字に母音チェンジを表すマークを付けて表記する。ひらがなでは「か」と「き」と「く」は全然違う独立の文字だが、インドの文字では क कि कु のように同じ क のバリエーションで表現する。 この例はデーヴァナーガリーだが、ほかの文字も基本的に同じシステムになっている。
ヘブライ文字やアラビア文字の知識がある方は、それらと同じシステムだと思うかもしれない。 確かによく似ているが、インドの文字では母音記号がつく場合は必ず書いて省略可能ではない、という点が違う(ヘブライ語やアラビア語では母音記号を省略することが多い)。
ここでインドの文字と呼んでいるのは、インド語派(主にインド北部)で使われるデーヴァナーガリー、ベンガリ、オリヤーなどだけでなく、 ドラヴィダ語(インド南部)で使われるカンナダ、タミル、マラヤーラムなども含む。 後者は言語としてはインドヨーロッパ語族ではなく、全然別だが、文字システムは同じ系統だ。 余談だが、日本のひらがなも恐らくある程度、この文字体系から影響を受けている。 インドの子音字の伝統的な並べ方をちょっと抜粋すると「カ…チャ…タ…ナパ…マ…ヤラ…ヴァ」となっていて、 ひらがなの五十音表の「カサタナハマラヤワ」との相似は偶然と思えない。 歴史的にも、デーヴァナーガリー系の文字は日本で「梵字(ぼんじ)」として神聖視され、 現代でも宗教や漫画やファンタジーなどではよく登場する。
ほとんどのインドの文字は英語などと同じく左から右に書くが、 母音記号は必ずしも子音字の後ろ(右)に付くとは限らず、逆側(左)や上や下に付くこともある。 実際、上の例で कि ki はkaの字の左に記号が付加されているし、 कु ku はkaの字の下に記号が付加されている(環境によっては正しく表示されない可能性もある)。
タミル文字、マラヤーラム文字などでは前後両側に付く母音記号もあって、Unicode規格では two-part vowel と呼ばれている。
具体的にマラヤーラムで、オー(長いオ)の母音は、![]() ...
... ![]() という記号で表す。
という記号で表す。
![]() が左に
が左に ![]() が右に子音字をはさむように付加され、
例えば、
が右に子音字をはさむように付加され、
例えば、
![]() ka にこの記号が付くと、
ka にこの記号が付くと、
![]() kō になる。
形式的には2種類の記号を前と後ろに付加するので、
Unicodeでは母音記号を2個書く形でも表現できるようになっている:
kō になる。
形式的には2種類の記号を前と後ろに付加するので、
Unicodeでは母音記号を2個書く形でも表現できるようになっている:
表示 കോ = 論理順序 ക + ോ (または ക + േ + ാ でも同じ)
通常は1つのコードで前後両方のパーツを表すが、分けて書いても(内部的な文字コードが違うというだけで)意味は変わらない。また、
表示位置が上下左右どこであろうと、論理的に(≒発音上)子音の後ろに付く母音はUnicodeのコードでは子音+母音記号の順序で表す。
例えば、デーヴァナーガリーの ki で i の記号は表示上は ka の字より前に来るが、だからといって、文字コード上で i + ka の順序で書くことは決してせず、
あくまでkiはka + i と表現する。(kaiにはならない。母音記号とは母音付加ではなく母音変更を表す記号と思ってほしい。)
なお、母音記号を単体で表示すると点線で書いた円 ◌ が一緒に表示されることが多いが、
これは子音文字の来る位置(相対的に言えば母音記号の位置)を示すもので、それ自体は母音記号の一部ではない。
以下、Unicodeのマラヤーラム文字の規格で例示されているアーントー(Ānṯō)という名前(固有名詞)について。環境によってはフォントがなくて表示できないかもしれないが、
ā は ആ という文字、
nṯa は普通「 ൻ の下に小さい റ を書いた文字」で表す。
これは2文字を一つにまとめて文字(リガチュール)で、 ൻ は n を表す要素、റ はこの場合 ṯa を表す要素。
「 ൻ の下に小さい റ を書いた文字」に母音記号 ō を付加すると、上記のように、左右に囲むような形になる。
![]()
ところで、「 ൻ の下に小さい റ を書いた文字」の代わりに、
ൻ と റ を並べて書くこともできる。この2文字はそれぞれ単体ではnとṟを表しているのだが、
この順序で並ぶと本来のnṟでなくnṯの音を表す。
例えばローマ字でもcとhを並べるとcともhとも関係ないチの子音になったりするが、同じこと。
2文字の組み合わせで特別な音を表している(ディグラフ)。
![]() この場合も、ā は ആ で同じ、
次に単体の n を ൻ と書いて、
その後ろに「この位置では ṯa の音を表す」 റ の文字を書く。
そして、この റ を囲むように母音記号を付けている。
この場合も、ā は ആ で同じ、
次に単体の n を ൻ と書いて、
その後ろに「この位置では ṯa の音を表す」 റ の文字を書く。
そして、この റ を囲むように母音記号を付けている。
注: ISO方式の音写でマラヤーラム語を表記するとき、ただの t の文字だと、英語の th に近い「歯と舌先で発する音」を表す。マラヤーラム文字では ത で、一般的には th と転写されることも多い。 一方 റ で表される ṯ は普通の [t] に近い音(書き方はリガチュールでもディフラフでも同じ)。 t に下線が付いているのはその区別のためだが、ここでは関係ない。
Ā + nṯa + ō と nṯa を一文字で書くか(リガチュール)、 あるいは、 Ā + n + ṯa + ō と n + ṯa を二文字に分けて書くか(ディグラフ)、の違いによって、母音記号 ō の左半分がどこに行くかが異なる。 前者では nṯa は一文字なので、表示上 nṯa の左に行く。 後者では ṯa は独立した文字でその ṯa の母音aを ō に変更するのだから、当然 ṯa の左、結果的に n より右に行く。
繰り返すと、
nṯa を一文字で書くなら
![]() 母音記号
母音記号![]() は n を表す ൻ より左に行く。
本来は ൻ と റ の間に来るはずだが、その2文字が一文字に結合して1単位で書かれているので割り込む隙間がないのだ。
nṯaを二文字で書くなら普通に
は n を表す ൻ より左に行く。
本来は ൻ と റ の間に来るはずだが、その2文字が一文字に結合して1単位で書かれているので割り込む隙間がないのだ。
nṯaを二文字で書くなら普通に
![]() 母音記号
母音記号![]() は n を表す ൻ より右に来る。
は n を表す ൻ より右に来る。
Unicode規格でも表示はちゃんとそうなっている。
問題は、Unicode 5.2.0の9章、Table 9-30で後者のコードが「アー」+「ン」+「母音記号オーの前半」+「タ」+「母音記号オーの後半」になっていることだ。
表示順序は確かにそうだが、論理順序はそうではない。 最初に強調したように、 表示位置がどこであろうと論理的に子音の後ろに来る母音は文字コードでは子音のコードの後ろに来るのが大原則なのに、 Table 9-30は「リガチュールかディグラフかで母音記号の表示位置が変わる」ことを強調することに心を奪われ過ぎて、 この原則を破ってしまっている。
「アー」+「ン」+「母音記号オーの前半」+「タ」+「母音記号オーの後半」というコードでは、 一つの母音を一つのコードで書く常識的な「アー」+「ン」+「タ」+「母音記号オー」と正規化で同等にならない。 「アー」+「ン」+「タ」+「母音記号オー」をNKD変換(Unicodeの定義上、同じ意味と認められる分解)しても、 「アー」+「ン」+「タ」+「母音記号オーの前半」+「母音記号オーの後半」であるはずで、 あくまで論理的に後ろに来る母音は論理的に後ろに来るべきだ。
この部分の規格には chillu に virāma が付くという直観に反する内容を含んでいるので、 もしかすると chillu に母音記号が付くのも意図的なのかもしれない。しかし非常に疑問に思う。
「インドの文字で、子音字にはデフォルトで-a」が付く、と最初に書いたが、わずかながら例外があり、上記 ൻ の字は na ではなく単に n と読んでいる。 一般に、インドの文字はたいてい純粋子音の m と h を表す記号を持っており(ただし歴史的にはこれらは単純な子音ではなかったようだ)、その m の変化で純粋子音の n が現れることもある。 しかし上記 ൻ はそれとはまた異なり、これはインドの諸文字の中でも特殊な性格の文字(または字形)だ。 chillu という用語はこの特殊な字形を指す。
サンスクリットの知識がある方は、どうして na + virāma で済ませず、 chillu n が別にあるのか…と疑問に思われるかもしれない。 サンスクリットの感覚だけでマラヤーラム文字を見ると同じ n を表す方法が少なくとも2通りあるように思える。
いちばん簡単な説明は「chillu とは子音文字+viramaのリガチュール」というものだが、これは部分的には正しいが、本質を突いていない。
ドラヴィダ語ではインドヨーロッパ語族より母音の種類が多い。 明らかに困るのはeとoの短音で、 インド語派には一般にこの音素がないので、インドの主流の文字ではこれを書き表す方法がない。 現代のタミル文字やマラヤーラム文字では新しい母音記号を追加して問題を解決している。 マラヤーラム語などではそれに加えて第6の母音、いわゆる half u の存在もあった。 half u を表記するためにさらに新しい母音記号を発明すれば良かったのかもしれないが、 実際には virāma を母音記号または母音記号の一部に転用するということが行われた。 副作用で virāma が多義的になり「絶対的な無母音=純粋子音」を表すことができなくなった (正確に言うと、half u は母音記号u+virāmaであいまいさなく表記できるはずだったが、歴史的な経緯であいまいになってしまった)。 よって純粋子音を明示的に表す別の文字が生まれた。 それが chillu の正体だろう。 ではなぜそこで anusavāra (サンスクリット文法でいうところの「代用」anusavāra)を使わないか…サンスクリットの知識がある方ならそう考えるかもしれない。 前提として、chillu文字はchillu nだけでないので、仮に chillu n の代わりに anusavāra を利用できたとしても chillu 文字一般の必要性は別問題となる。 chillu n 自体も anusavāra では代用しにくい。 マラヤーラム文字の anusavāra は語末では既に“chillu m”(正式にはそういう言い方はしないが)として用いられているからだ。 n を代用anusavāra で表記すること自体は場合によっては(つまりt-vargaの直前では)考えられるが、一般論として、もし語末で anusavāra が n を表すことができるとすると、その文字が表しているのが m だか n だかあいまいになってしまう(マラヤーラム文字では、実際には語末のanusavāraはmを表している)。 それでは virāma の多義性を排除するために文字を変えた意味がなくなってしまう。
つまり「語末の na + virāma は n + half u を表しうるので、明確化のために、特に語末の純粋な n を表す文字を考える」という趣旨に照らすと、語末の anusavāra は m を表しうるので、 anusavāra で置き換えても明確化になっていない。 逆に言うと、サンスクリットにいうanusavāraがなかったら、今ごろ語末の m を表すために chillu m という文字ができていたに違いない。
場合によっては、na + virāma の virāma が普通に無母音を表すこともあるが、一般には、 na + virāma と chillu-n は、nの後ろにつく母音( half uか無母音か)を区別する意味を持つ。 ドラヴィダ語では n に似た子音が何通りもあってサンスクリット以上の書き分けが必要になる、というのは事実だが、chillu n は子音 n 自体を書き分けるためにあるわけではない。 インドの文字の通常の発想とは大きく外れて、「母音」を区別するために新しい「子音」文字を作ってしまった。 歴史的な偶然の積み重なりとはいえ奇妙な存在であり、これらの文字をめぐってはUnicode規格や実装もいまだに混乱している。

{kind=link}
{kind=link}
{kind=link}
{kind=link}