「
ある数 x が素数 p を法として平方数であるかないか。言い換えれば、x と p が与えられたとして
y2 ≡ x (mod p) …… ①
を満たす y が存在するかどうか。
この問題は理論的に重要であるだけなく、応用上も、ソロベイ・ストラッセンの素数性判定に結びつく。
さらに楕円曲線暗号においても、ℤp上の楕円曲線
y2 ≡ (x の3次式) (mod p)
の点を求めるには、右辺が平方数であるかどうかという問題に帰着する。
いま定数pを3以上の素数とする。以下、すべてpを法として考える。 (まわりくどい言葉遣いはしたくないので、整数とそれが属する剰余類を同一視する。) ある整数xが与えられたとして、xが平方数であるかどうか知りたいとする。 言い換えれば、①を満たすyがあるかどうか知りたいとする。 pが小さければ、yに1, 2, 3, ... を代入して≡x になるケースがあるかどうか片っ端から調べるのでもいいが、 我々のpは何十桁あるいは100桁以上もあるような巨大素数なので、そんな悠長なことはやっていられない。 実際に解を求める泥臭い計算をせずに、透明に、ただ解があるかないかという、それだけを知りたい。
さて、フェルマーの小定理の合同式の肩の数字を半分にした形:
x(p-1)/2 ……②
は、≡1 または ≡-1 となる。
フェルマーの小定理より (p-1) 乗すれば≡1は分かっているので、その平方根にあたる②は±1になる。
法が素数のとき、2乗して1になる数は±1に限られるからだ。
(ただし、x は p の倍数ではないとする。
x が p の倍数なら x≡0だから、②は、もちろん0になるが、このような場合には興味がない。
なぜなら我々の p は実際には巨大な素数であって、そのさらに倍数であるような x など興味なく、
p 未満の数だけで世界は完成するからだ。もちろん p 未満には p の倍数はない。)
もし② が ≡ 1 なら、① を満たす y が存在する。②が ≡ -1 なら①を満たす y は存在しない。 平方数かどうか?を判定するオイラーの規準だ。
①を成り立たせるyが存在したとしよう。
つまり、x ≡ y2 と書けたとする。
これを使って②を書き直すと、
(y2)(p-1)/2 ≡ yp-1
となるが、フェルマーの小定理からこれは≡1だ。
逆に、②が≡1になったとしよう。
このとき、適当に選んだ原始根 b を使って x ≡ bα と書いたとすると、②は
(bα)(p-1)/2 ≡ b(α(p-1)/2)
となるが、これが≡1になると仮定している以上、指数 (α(p-1)/2) は (p-1) の倍数でなければならない。
b は原始根で、(p-1)乗して初めて≡1になるからだ。
もし指数 (α(p-1)/2) が (p-1) の倍数でなければ、
(α(p-1)/2)を (p-1)で割った0でない余りをβとでも書くとして、
bβが≡1になってしまう。しかもβはp-1 より小さい。
これでは b として原始根を選んだ、という仮定と矛盾してしまう。
指数 (α(p-1)/2) が (p-1) の倍数であるということは、要するにαが2の倍数(偶数)であるというだけの話だ。
もし α が奇数だったら、上記の指数は (p-1)の1.5倍または2.5倍または3.5倍……というふうに0.5の端数がついてしまって、
きっかり倍数にならないからだ。よって、α/2 は整数であり、
b(α/2)
は意味を持つ――それは「二乗すると≡bαになる整数」であるが、
x ≡ bα なのだから、結局、二乗すると≡x になる数が存在したことになって、
①は解を持つ。
まとめると、①が成り立つなら②は≡1となるし、逆に②が≡1となるなら①は成り立つ。 ①が成立する・しないは、②が≡1になる・ならないと連動している。 ところで、 ②は≡1か≡-1かのどっちかになるのだから、 ①が成立しない場合――言い換えれば②が≡1にならない場合――には、②は≡-1にならざるを得ない。 そんなわけで、①に解があるかどうかを知るには②を計算して結果が+1になるか-1になるかを見れば良いのである。
素数9973について。
850MHz程度のクロックのPC上でJavaScriptを使った場合、法pが100万くらい(つまり7桁くらい)までは、片っ端から可能性を試すことで、 平方数であるかどうか簡単に判定できる。しかしpが8桁、9桁……となると1桁増えるごとに計算量が10倍になるので、力ずくでは無理がある。 オイラーの規準の出番だ。次のリストでは、8桁の素数 12345643 を法として、y2 ≡ 7 が整数解を持たないことを示す。
// 強引な方法
// あれば平方根を返し、平方根がなければ0を返す
function QuadraticResidue( x , p ) {
for( var y=1; y < p/2; y++ ) {
if( y*y % p === x ) {
return y;
}
}
return 0;
}
// オイラーによる判定法
// 平方剰余ならtrue、そうでなければfalseを返す
Bigint.prototype.isQuadraticResidue = function( modulus ) {
var oModulus = Bigint.serio( modulus );
var oResult = Bigint.powmod( this, oModulus.minus(1).half(), oModulus );
return ( oResult.isEqualTo( 1 ) );
}
ver p = 12345643;
ver x = 7;
_Debug( "Brute" , QuadraticResidue( x , p ) );
_Debug( "Euler" , Bigint.Number( x ).isQuadraticResidue( p ) );
この例の場合、 オイラーの規準を使った方法では、0.1秒ほどで判定できる。 一方、強引な方法の場合、p2 が約47ビットの長さなので JavaScriptの組み込み整数型(53ビットまで)でまかなえるものの、 それでも手元の環境では10秒以上かかった。 8桁でこれなのだから、我々が問題にする数十桁以上の素数では話にならない。
最初の例で、素数9973を法とするとき、3は平方剰余で5は平方非剰余であることを示した。 このことを「対数的」に考えてみよう。すなわち……
まず原始根をひとつ求める。フェルマーの小定理によって、9973-1=9972乗すれば必ず≡1になるが、
原始根であるためには、それ以前に≡1になってはいけない。9972を素因数分解すると
9972 = 22 × 32 × 277
であるから、(9972を2、3、277で割って)4986乗、3324乗、36乗のいずれでも≡1にならなければ、9972乗より手前で1になることはないだろう。
そのような数を探すと11が見つかる。
11(9972/2) ≡ -1 (mod 9973)
11(9972/3) ≡ 1569 (mod 9973)
11(9972/277) ≡ 6437 (mod 9973)
次に、平方剰余である3が、11の何乗として表せるか考えてみる。
11x ≡ 3 (mod 9973)
この方程式の計算は、離散対数と呼ばれるものの一種だ。
実数上の普通の指数・対数関数と違って増え方が一様でなく、xが1ずつ増加するにつれて、(剰余類の代表として0~9972をとった場合)大きくなったり小さくなったり、予想が難しい挙動をする。計算も面倒くさい。
11が原始根である以上、xに1, 2, 3,...を代入すればどこかで≡3になるのは確かなのだが。
ともあれ、この例では、119300 という約9700桁のばかでかい数が ≡ 3 となる。
つまり、
log113 ≡ 9300 (mod 9973)
だ。この数が平方数であることは、具体的に、
119300/2
の二乗が≡119300であることから明らかだ。
119300/2≡3291の平方が3と合同になることはすでに見た。
同様に、平方非剰余である5が、11の何乗として表せるか考えてみる。
11x ≡ 5
答は x=3093 だ。
つまり、
log115 = 3093
もしこの対数値が偶数であったなら、その半分をべきとする数の2乗が≡5になれたはずである。
それは5が平方数でない(平方非剰余)という事実と矛盾する。
つまりこの場合、対数値は奇数でなければならない。
平方剰余か非剰余か? という区別は、離散対数をとった場合に偶数か奇数か?という区別と同じことだ。 離散対数は計算が大変なので、この方法は平方剰余・非剰余の判定法として実用的ではない。
余談だが、 11を底とする離散対数の表を作るには、a=11, b≡a*11≡112, c≡b*11≡113, ... のように次々と底を掛け算しながら先に進んでゆけば良く、 アルゴリズムは単純だが、例えば法が10桁あるとすると見出しが10億以上あるテーブルを作らなければならない。 時間的計算量のみならず、空間的計算量もばくだいだ。 法が数十桁以上の場合、こんなふうに離散対数でマスクされると、単純に逆変換表を作ってクラックするのは困難だ。
PDFを障害者にも使いやすいものにしよう。 真剣な努力が行われている。 しかし、まだ成功とは言えない。
PDF というファイル形式は、昔から、障害者でも使いやすく、といういことを目指してきた。 しかし、その理想は、2004年の現在でも、まだ実を結んでいない。 むしろ、PDFは、インターネットのページで最も良く使われる「HTML」に比べて使いにくいという不満が大きい。
バリアフリーとはバリア(妨げ)を取り除くことだ。 PDFを障害者にとって使いやすいものにしようと考えるとき、 そもそもPDF自体がバリアになっているのだ、という事実をよく考える必要がある。
テキストが基本のMS-DOSの時代、視覚障害者にとって、パソコンは便利な道具だった。 ところが、時代が変わった。 「GUI」と呼ばれる、目が見えないと分からない種類の情報が、パソコンの操作の中心になった。 晴眼者のパソコン初心者には便利になったが、 視覚障害者にとっては、かえって不便になった。
晴眼者は、シンプルなテキストの情報を、つまらないと感じる。 絵がある方が、楽しくて利用しやすいと思う。 ところが、視覚障害者には、ただのテキストの方が、ありがたい。 絵で説明されると困る。
2004年時点において、PDFの使用は、どうしても必要でない限り、避けるべきだ。 なるべく使わない。それが「障害者のためのPDFの使い方」であり、 健常者にとっても、その方が良い。
手に障害があるインターネット利用者も、ブラウザを使えるように努力して、工夫している。 PDFを読むのに必要なプロフラムは、通常のブラウザとはまた別で、 新たに使い方を覚えなければならない。余計な労力を無理強いすることになる。
しかし、PDFは例えば印刷するのに、便利だ。 使いどころをわきまえれば、役立つ。 すべてが悪いという訳ではないし、 障害者の都合だけで、健常者にとって役立つことのあるものを、なくそうとは思わない。
この記事では、次のトピックを紹介する。 視覚障害者がPDF文書を利用しやすくするサービス。 PDFファイルは日本語が苦手。 Acrobat Reader 7.0 Beta の印象。
最後に、他のサイトの記事を二つ紹介して、リンクしてある。 「PDFとアクセシビリティ」という記事の紹介。 PDFは障害者のために努力しているという肯定的な立場だ。 「PDF: 人間が消費するのには不向き」という記事の紹介。 こちらはPDFは不便なので、なくした方がいいという否定的な立場だ。 両方の立場があることが分かる。
要約の終わり。もくじに戻る a。
PDF文書それ自体が、アクセス性にとっては、好ましくない。 ユーザビリティの権威である Alertbox ではPDFは犯罪的と言い切り、 Alertbox 200号では「PDF 撲滅の戦い」という言葉まで使っている。
PDFがいかに迷惑か、については、誰もが経験している。 PDFを開くぞ、と心の準備ができていればいいのだが、 ウェブをブラウズしているとき、それと知らずにPDFへのリンクをクリックさせられると地雷を踏んだような気分になる。 うわっ、しまった。PDFだったのか。それならそうと書いておいてくれればクリックしなかったのに…と思いながら、 のろのろとリーダーが立ち上がるのを待つ。 キャンセルはできない。我慢して時が過ぎるのを待つしかない。 それがまた途中でフリーズしたり。 コピー&ペーストがしにくいのも情報の再利用性を悪くしている。
これだけの代償を支払ってまでPDFを使う意味は何か。 プラットフォームに依存しないという伝説があるが、日本語環境外で日本語のPDF文書を開こうとすると、 フォントのダウンロードから始まる。つまりはオンラインでないと文字化けして読めない。 最初から日本語版のPDFリーダーを使えばいい、と思うかもしれないが、それではPDFリーダー側のメニューが文字化けして読めない。
特にHTMLで書けるただのテキストを、わざわざPDFにしてあるのは本当に迷惑だ。
HTML 3.2 の時代ならいざ知らず、現代では、 Mac/Win/Linux 上のほぼすべてのブラウザで同様に見えるHTMLページを作れるのだから、 相対的に、クロスプラットフォームの実現という観点でのウェブ上でのPDFの存在価値は、低くなった。 数学の論文では好まれるのだが、数式を画像で表現したHTMLページも増えていて、 使う側からすれば、たいていその方が便利だ。そして、やはり長期的には、テキストストリームとして処理できる MathML のような方向に行くべきだろう。 ウェブページと XML と Maple で直接コピーペーストができたら、どんなに便利か言うまでもない。
PDFは物理的にプリントアウトする、という用途、 または、物理的な紙のイメージを再現する、という用途においては便利なのだが、 情報を利用する、という観点からは、そもそも物理的な紙などはどうでも良く、 プレーンなテキストの方がかえって扱いやすい。
PDFは、テキストリーダーを用いる視覚障害者にとって、特に問題となる。 HTMLページは簡単に読み上げられても、PDFとなるとまた別の技術が必要だからだ。 プリントアウトに便利、ということは視覚障害者にとってはほとんど無意味だ。 しかし、各国の政府機関などでPDFは多用される傾向にある。 経緯はともかく、既に多用されているという現実は動かせない。
PDFの開発元であるAdobeでも、PDFのアクセス性を良くする努力をかなり前から続けてきた。 HTMLと比べてPDFが障害者に厳しいフォーマットであることを認識したうえで、 PDF自身に障害者のアクセス性を考慮したさまざまなスペックをつけた。 PDF自体についての評価はさておき、この努力は評価されていい。
しかしながら、そういう仕様があっても、PDFを作成する側がそれを利用しないことには、結局、障害者のアクセス性は改善されない。 絵に描いた餅、使えば使えるけれど使われていない機能、HTMLのlongdesc属性のようなもの。
この状況で登場したのが、 Open Access だ。 障害者が利用しやすいようにPDFにタグをつける作業を、自動的にしてくれるウェブサービスだという。 変換したいPDFをアップロードすると、サーバ側でアクセス性を改善したPDFにしてくれるのだという。 9月にサービス開始だという。
これはこれで現実的に結構な話なのだが、当然の疑問もある。 自動的にタグを打てるウェブアプリが作れるなら、そもそもそのアルゴリズムが何でアクロバット自身に入っていないのだろうか、ということだ。
繰り返すが、PDF形式が絶対的に悪い訳ではない。 例えば、紙に印刷して持ち歩く用途には適している。 ただ、ウェブページからリンクした場合、HTMLと比べて利用しやすさに段差があるのも否定できない。 PDFをどういう場面で使うべきで、どういう場面で使うべきでないか、よく考える必要がある。 「これをプリントアウトして記入して郵送してください」という申請書のフォーマットなら、PDFも合理的というものだが、 ただの議会報告書や、ゴミの出し方の注意などをPDFにする意味はほとんどないはずだ。 特に政府機関のウェブサイトの情報は、当然、障害者でも利用しやすい、バリアフリーを志向すべきなのだが、 一部の優秀な例外を除いて、なかなかそうなっていない現状がある。 健常者でさえHTMLより利用しにくいと感じるPDFの使用については、特に慎重でなければならないはずだ。
このメモを書いたきっかけは、The Register の、次の記事です。 PDF tagging for the blind
もくじに戻る a。
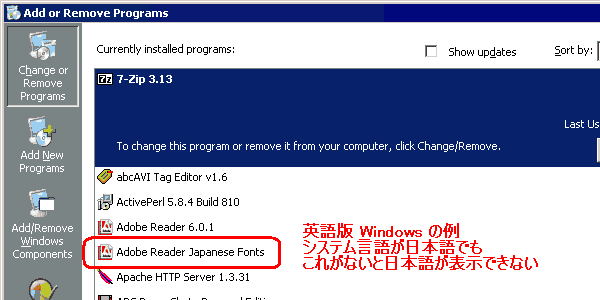
 Acrobat Reader 5.x から名前を変えたAdobe Reader 6.0 の、日本語版が出ている。と同時に、ほかの言語バージョンで、日本語フォントの自動ダウンロードができるようになった。
Acrobat Reader 5.x から名前を変えたAdobe Reader 6.0 の、日本語版が出ている。と同時に、ほかの言語バージョンで、日本語フォントの自動ダウンロードができるようになった。
当初6.0の英語版が出たとき、日本語のPDFファイルが文字化けしてしまうという致命的な欠陥があった。 「PDFファイルはプラットフォームに依存しない」というのは単なる建前であり、事実ではない。 CJK(中国・日本・韓国)の文字を含むPDFファイルは、フォントがPDFに埋め込まれている場合でさえ、 フォントを追加ダウンロードしないと一般の環境では文字化けしてしまう。 これはAcrobat Reader 5時代からの「仕様」であり、最新の6になっても変わらない。 Adobe の資料「日本語版と英語版のデータの互換性はありますか」でも、しおり(もくじ)の文字化けは「アジア言語フォントパック」をインストールしても解消しないと、 説明されている。 しかも、6が出た当初、ヘルプファイルには「CJK文字があればフォントを自動でダウンロードする」と書かれていたのにもかかわらず、 実際にはこのダウンロードができなかった。まだフォントデータが準備できていなかったのだろう。 要するに、アドビは、テキストさえ表示できないようなとんでもない未完成の製品を正式の「最新版」として大々的にダウンロードさせていたのだ。
ともあれ、Adobe Reader 6 は日本語圏でも使用可能になった。日本語環境でのみ使うユーザは日本語版をダウンロードすれば良い。 一般の環境で使うユーザは、英語版などでも、日本語フォントを含むPDFファイルを開いたときに、 自動でアップデートを行える。

Adobe Reader 6のインストーラはあまり賢くないようだ。 Acrobat Reader 5がある場合は手動でアンインストールしてからAdobe Reader 6を入れないと二つのバージョンが無駄に共存してしまうようだ。
「PDFファイルはプラットフォームに依存しない」というのは嘘である、ということを繰り返し強調しておく。 「ASCII文字と画像だけ」でない限り、ユーザはPDFファイルを作成・配布すべきでない。 「ASCII文字と画像だけ」なら通常、HTMLで充分だ。数式を含む場合も、重いアドビ製品を使うくらいなら、MathMLとMozillaで軽快、フリー、効率的に行きたい。 MSIEでもMath PlayerをインストールすることでMathMLを解釈できる。
PDFにはPDFの良さがあるのも確かだが、PDFで配布すれば誰でも読めるとの間違った思いこみから、みだりにPDFを使うべきではない。 今回、日本語のフォントは使えるようになったものの、中国語、ロシア語などなどの一般の言語に対応しているのかどうかは疑わしい。 日本語圏の一般のユーザはそれらの文字とはあまり縁がないかもしれないが、 それにしても、こんな状態では、PDFを「環境に依存しない世界標準」などと認めることは絶対にできない。 HTMLならシステムにフォントさえあれば世界中の文書が表示できる。 それに対して、「フォントを埋め込んでおいても表示できない」というPDFは魅力に乏しい。 単に過去との互換性のためだけに存在するとさえ言える。
凝ったデザインの重いスプラッシュを起動のたびにこれ見よがしに表示するが、 スプラッシュなど作ってる暇があったら、肝心かなめのコンテンツの文字をちゃんと表示できるようにフォントまわりをきちんとしてほしい。 この愚かしさは、表紙だけは金をかけて立派だが、なかみは乱丁だらけで読めない本のようだった。
本文に述べたように、従来のAcrobat Reader 5の一般のバージョンも、CJKフォントパックを追加しないと日本語PDFを表示できない。 しかも当初、バージョンアップしてもCJKは表示できるという事実に反する表示があった。
自分のまわりには日本語環境しかない、というユーザはこの問題に気づきにくいかもしれない。 日本語を第一言語とするユーザであっても、さまざまな理由からさまざまな言語環境のOSを使っていることがある。 「わたしのまわりの人は誰も困っていないからPDFで良い」という個人的な考えで、一般配布されるといろいろと不都合が生じる。 その不都合が生じる割合が比較的少ないのであまり気づかれていないが、いくら割合が小さくてもプラットフォームに依存しているという事実に変わりはない。 「ASCII文字と画像だけ」でない限り、ユーザはPDFファイルを作成・配布すべきでない、というのは、 まあちょっと強すぎる主張ですが、インターネット用語でいうところの「すべきでない」という主張です。 「してはいけない」ではないです。一部の人しか読めないPDFなんて……。「CJKフォントパックがすでにあるか、インターネットに常時接続していてオンデマンドでフォントを追加できる環境でのみ読める」 というふうに特定の環境に依存すべきでない。
それは確かです。なんでも慣れていないこと、新しいことは面倒……。 「数式を含む場合も、重いアドビ製品を使うくらいなら、MathMLとMozillaで軽快、フリー、効率的に行きたい。」というのは「行きたい」という希望であって、 行くべきだという主張ではありません。PDFは慣れているから使いやすい、と心理的に感じる。それは確かに重要な要素でしょう。 つまり「単に過去との互換性のためだけに存在するとさえ言える。」
いろいろな事情で日本語版でないOSで日本語を使わなければいけないケースでは、 さまざまな問題を解決していかなければなりません。そして、そのような特殊なケースは特殊だから無視して良いとも言えるけれど、 一方、特殊なればこそ、本当に環境非依存でユニバーサルなのか?の試金石になるでしょう。 早い話、手元の環境では読めないPDFが珍しくなく、そうなると「本当にこれって環境に依存しないって言い張れるの」と常々疑問に思っていました。 そこへきて、バージョン6へアップのときの「CJKも大丈夫」というヘルプファイルの記述の誤りで、さらに気が滅入る思いをしたのです。 PDFのすべてが悪いという意味ではなく、自分自身ウェブ上で PDFで公開してるコンテンツ もありますし(ただし日本語の文字などは画像にしていますが……) 、 もちろんアドビに個人的恨みがあるわけでもなく、アドビの、SVG Viewerのフリー公開は素晴らしいことです。
もくじに戻る a。
 Acrobat Reader 7.0 Beta の印象
Acrobat Reader 7.0 Beta の印象Adobe Reader の軽量化(スピードアップ)用のツールに人気が出るなど、 遅さに難があった PDF だが、 この根強い不満に応えようということか、7.0 では起動がものすごく速くなった。 無意味なスプラッシュなど出さず、メモ帳くらいの軽さで、パッと立ち上がる。
Acrobatは、バージョンアップによって日本語の文字が正しく表示できないなどの問題が出ることが多いので、 導入は慎重に。 今回も、7.0 Beta に上げると、日本語のPDFは読めなくなる。6.0 用の Adobe Reader Japanese Fonts がインストール済みでも駄目(非互換)。 同じ問題は 5.0 から 6.0 のときにも起きた。あのときは「プラットフォームに依存しない」ことを売りにするはずのソフトの正式リリース版で、 アプリが英語版というだけで日本語が文字化けして当惑したが、今回は、まだベータ版なので仕方ない。 後からリリースされるはずのフォントパックを別途導入すれば、アプリの言語と無関係に各言語のPDF文書が開けるようになる。
分かりにくい独自インターフェイスのためウェブでHTML文書と混在すると使い勝手が悪い、 という根本的問題は未解決だが、今回の軽量高速化は大歓迎だ。
PDF は例えば HTML で表現しにくい数学の論文の場合など、うまく使えばかなり便利なものだが、 アクセス性の問題があることに注意。 例えば、市役所のホームページで「ゴミの出し方の注意」を PDF 文書で公開したとすると、 上述のように、日本語版以外のユーザが困るかもしれない。 その町に住んでいる外国人が、日常必要な行政サービスの情報にアクセスできなくなるかもしれない。 日本に住んでいるなら日本語版のソフトを使っているに違いない、といった勝手な決めつけに基づく「機種非依存」では機種非依存になっていない。 Windows 2000/XP のようなユニコード対応のOSを使っていて、ブラウザやエディタでは普通に日本語が表示できるのに、 PDF だとこうした問題がある。
PDF がプラットフォーム非依存というのは売り手の宣伝文句に過ぎず、実際には環境への依存度が高い。 だから悪い、というより、フォールバック用の基本多言語面デフォルトフォントを同梱するなど、何とか改善できるのではないか。 (印刷イメージにこだわるので、フォールバックができないというジレンマがあるようだが、 まったく表示できないよりは、 味気ない既定フォントででも読めたほうがずっといい。) 日頃、数学の論文でお世話になっているありがたい PDF なのだが、半面、多言語対応(いわゆるi18n)の弱さは残念だ。
Adobe Reader 7.0 Beta は起動が本当に速くなった。 起動時のスプラッシュが [PrintScreen] でキャプチャーできない。 そのくらい一瞬で起動する(デフォルトではスプラッシュを出さなくなった)。
インストーラが All Users の Startup に Adobe Reader Speed Launch という項目(%windir%\Installer\...\SC_Reader.exe)を登録することから、 OS起動時にバックグラウンドで起動して待機しているだけではないか、と思ったのだが、 スタートアップからこの項目を削除しても、起動時間の差はほとんど体感できなかった。 SC_Reader.exe 自体、通常の Win32アプリではなく、どのような機能があるのか不明。 スタートアップに登録した場合としない場合とでの実行プロセスの違いも、タスクマネージャからは検出できなかった。
日本語も表示できるし、軽いです。(ベータ版よりわずかに重くなった感じがあるが、6.0よりは問題なく軽い。)
ftp://ftp.adobe.com/pub/adobe/reader/win/7x/7.0/enu/AdbeRdr70_enu_full.exe
日本語版も出てます…。
Adobe Reader 7.0, full version
日本語も表示できると書いたが、間違いでした。6.0 と同じで進歩してません。 日本語のPDFでフォントがないとダウンロードしにいこうとはしてくれるのですが、 7.0用の日本語フォントパックがまだなく、ダウンロードできないという、6.0リリース時とまったく同じ症状。 日本語版の Adobe Reader は日本語を表示できるのかもしれませんが、 そんなのは MS-DOS 時代の発想で i18n というのはそういうものではない。 それではOS側のロケールが日本語でない限り、 Adobe Reader 自身のメニューが文字化けしてもっと使い物にならない。 いちいちロケール(コードページ)を切り替えないでBMP全面くらいはシームレスに網羅してほしい…。 6.0と同じでちょっと待てばフォントパックが出るかと…。
6.0より多少起動が早いですが7.0ベータは、もっとこの二倍くらい早かったんですよ~。 ベータよりかなり遅くなったが、6より速いので一応歓迎ですが…。
Acro-Reader_701_Update.exe は7.0 に対するアップデータで、セキュリティホールを含むいくつかのバグを修正する。 Adobe Reader 7.0.1 update - multiple languagesに説明がある。
手元では、7.0では日本語フォントが自動でインストールできず、7.0.1では自動でインストールできた。 スウェーデン語版でも問題が確認されている。 Adobe Reader 7.0 は国際化対応しておらず、 ロケールと違う言語のブックマーク(日本語版では「しおり」)は一般に文字化けする。 言語のフォントは必要に応じて個別に導入。 例えば、日本語のフォントがない場合、 自動ダウンロードか、または、 alf_jpn.exe。
右上に表示される飾りのロゴは設定で消すことができる。 きれいなアニメーション・ロゴは見ていて楽しいが、文章を読むときにチラチラされると気が散るので、非表示の設定にしておくと良い。 ツールバーにも必要性の低いボタンがデフォルトで表示されているから、使わないボタンは非表示にしてすっきりさせよう。
もくじに戻る a。
アクセス性とかアクセシビリティとは、情報の利用しやすさのことだ。 「利用しやすさ」が最低最悪だと、そもそもまったく利用できない。 絵だけで説明されて文字による補足説明がなければ、視覚障害者にとって、アクセシビリティはほとんどゼロになる。 利用できない訳ではなくても、 非常に苦労しないと利用できないような情報は、アクセシビリティが低い、と言う。 困ったことだ。 ユーザビリティというのも、だいたい同じ意味だ。 「PDFとアクセシビリティ」という記事には、こう書いてある。
私がPDFとアクセシビリティの問題に興味を持ったのは、W3Cのアクセシビリティ関係のページをうろうろしていて偶然access.adobe.comに行き着いた時からです。単に代替手段を提供するだけでなく、アクセシビリティの問題とその解決手段を、今後の製品スケジュールに織り込んで説明していることに好感を持ちました。電子文書としてのデファクトスタンダードたらんとするPDFのスケールの大きさとも言えるでしょう。
ただし、Acrobat 5.0の時点では、access.adobe.comが日本語をはじめとする2バイト文字の言語はサポートしていないなど、日本語環境でのアクセシビリティの確保はまだこれからといったところです。
日本ではPDFのアクセシビリティについてはまだほとんど問題になっていません。というよりも、Webサイト自体のアクセシビリティに注意が払われていません。官公庁のWebサイトでも、画像にalt属性で代替テキストが付けられていない、フレームのリンク先が不明確といった例が多々あります。
リンク先の記事では主に障害者のアクセス性が問題になっている。 アクセス性は、クロスプラットフォームや多言語混在環境においても重要だ。 Windowsを使っている人しか読めない、Internet Explorerを使っている人しか読めない、 OSが日本語環境でないと読めない。そういう情報は、アクセス性に問題がある。
「PDF:人間が消費するには不向き」という記事は、とても参考になる。
理屈はどうあれ、実際のユーザーがPDFを嫌っているという現実を踏まえないかぎり、 ユーザビリティの議論は成り立たない。ただし、この記事は数式のことは考慮していない。 数式を使う必要があるのでPDFやPSにお世話になっているのであって、 それは印刷に便利というのとは違う観点だ。
ユーザはPDFがきらい
最近のいくつかのユーザビリティ調査で、PDF ファイルに遭遇したユーザから悲痛な不満の声が聞こえた。
以下は、企業ウェブサイトの投資家エリアのテストに参加した投資家たちの発言である。
「PDF をいちいちダウンロードさせられるのは苦痛ですね。頭痛のタネですよ。イライラしてしまいます。読み込みも遅いですし、中身を検索するのもたいへん。 HTML の方が扱いやすいですね。チャートのかわりに、全部 PDF になってますよね。私の理想のサイト、それは過去 10 年の売上のバーチャートがすぐに入手できるサイトなんです」
「Adobe Acrobat は大嫌い。PDF があっても、一部を選択、コピーして Word に移すことはできません。必要のないグラフィックなんかが入っていたりしますしね。文書は HTML の方がいいですよ、編集できますから」
以下は、企業ウェブサイトのPRエリアのテストに参加したジャーナリストたちの発言である。
「あれ(PDF ファイル)は、ウェブページらしくないよね。スピードの問題じゃないんだ。流体の代わりに固体を与えられたみたいな感じ」
「で、手に入ったのが PDF 文書。プリントアウトにはいいけれど、画面上では読みにくいんです。文字が小さすぎて」
「Acrobat には少し不満があります。全ページがひとつのファイルになっているんです。それでどうなるかというと、スクロールするとジャンプしてしまう。これではあまり役に立ちません」
以下は、イントラネットのテストに参加した従業員の発言である。
「1 ページ目がインデックスになっていて、そこへスクロールできるようになっていると助かるでしょう。横についている部分はそのためのものなんでしょうけど。誰にいえばいいんでしょうね?」
最後の発言からも明らかなとおり、PDF ファイルには独自のナビゲーション補助が装備されているが、ほとんど役には立っていない。なぜなら、それは非標準的であり、ハイパーテキストのナビゲーションではなく、紙のメタファーにもとづいたものだからだ。
この他の数多くの調査でも、同様の反応が返ってきた。その中にはB2B のウェブサイトも含まれていたが、製品スペックや顧客の成功事例をウェブページではなく PDF で提供している点に、ユーザは不満を表明した。以下は、サイト内で PDF になっていたその種の部分を避けて通った顧客の声である。
「どうやら PDF へ行かざるをえないようですね。でもそれだけは絶対にいやなんです」
もくじに戻る a。