RSA暗号は、ℤp上でのべき乗に対する逆算(つまり離散対数)が計算量的に難しいことを基礎にしている (触って分かる公開鍵暗号RSA)。 楕円曲線を用いて、これとよく似たことができる。 いわゆる楕円曲線暗号だ。ただし、以下で説明するアルゴリズムが楕円曲線暗号のすべてではなく、 このほかにも楕円曲線を使った暗号システムはいくつか種類がある。 逆に楕円曲線を使った巨大整数の因数分解──RSA暗号への強力な攻撃法──もある。 楕円曲線は「戸締り」(暗号)と「金庫破り」(暗号解読)の両方に応用があるおもしろい世界だ。
楕円曲線
y2 = x3 + 2x - 1 ……①
を、ℤ7上で──言い換えれば、mod 7 で──考えてみよう。手っ取り早く言えば、
y2 ≡ x3 + 2x - 1 (mod 7)
を満たす (x, y) を考える。
例えば、 (1, 3) は、①を満たす。
左辺: 13 + 2×1 - 1 = 2 (mod 7)
右辺: 32 = 9 ≡ 2 (mod 7)
mod 7 で考えているので、可能な x と y の組は49通りしかなく、スクリプトを使ってしらみつぶしに調べることで、 簡単に①を満たすすべての点をリストアップできる。
(1, 3) (1, 4) (2, 2) (2, 5) (3, 2) (3, 5) (4, 1) (4, 6) (5, 1) (5, 6)
これら楕円曲線上の点の上に、次のような演算を定義すると、群になる。
すなわち、(x1, y1) という点と、
(x2, y2) という点の「和」 (x3, y3) を、次のように約束する。
x3 = λ2 - x1 - x2
y3 = λ(x1 - x3) - y1
λとは何者か?というと、異なる点を足す場合、つまり一般の場合には
λ = (y2 - y1) × (x2 - x1)-1
とする。同じ点を足す場合、これでは分母分子ともゼロになってしまうが、その場合には、
λ = ( 3x12 + a ) × 2y1-1
とする。
a とは楕円曲線の1次の係数で、①では2である。
さらに、x1 = x2 で y1 = -y2 というケースがある。
その場合、足し算の結果は「無限遠点」とする。「無限遠点」自身は、この演算に関してゼロとして機能する。
ここで-1乗というのは逆数(ℤ7上でかけると1になる相手の数)のこと。
いかにも天下り的で、わけの分からない定義に見えるだろう。 ℤ7上で考えているので普通の座標平面でグラフで書いて説明できないのだが、 普通に実数上でやった場合は、非常に明快な幾何学的な意味がある。 しかし、その幾何学的意味は暗号の本質と関係ないので、ここでは抽象的な演算として、純粋理性的にとりあえず受け入れてほしい。 ここで考える楕円曲線は、有限体という有限な範囲(あるところまで行くと元に戻る世界)に閉じ込められている。 「ガラスびんのなかに、透きとおった楕円曲線が、人間の目では認識できないふしぎな姿でくるる…と詰まっている」とイメージしておこう。 何が何やらよく分からないと思うが、それでよい。 よく分からないけれど、とにかく規則に従って扱うことができる抽象的な「何か」なのである。
そんなことより、本質的に重要なのは、この演算に関して、さきほどの10個の点(無限遠点を含めて11個の点)が閉じている、ということである。 点に名前がないと議論の見通しが悪いので、次のように名前をつけて、 「点」の代わりに「妖精」と呼ぶことにする。
(1, 3) あるる (1, 4) あれれ (2, 2) きりり (2, 5) きろろ (3, 2) さりり (3, 5) さろろ (4, 1) たらら (4, 6) たわわ (5, 1) ならら (5, 6) なわわ (∞, ∞) 無限遠点
公式にしたがって、ためしに、「さりり」と「たわわ」を足してみよう。
「さりり」(3, 2) と「たわわ」(4, 6) は
異なる妖精なので、
λ = (y2 - y1) / (x2 - x1)
= ( 6 - 2 ) × ( 4 - 3 ) -1 = 4 × 1-1 = 4
ゆえに、
x3 = λ2 - x1 - x2
= 42 - 3 - 4 = 9 ≡ 2 (mod 7)
y3 = λ(x1 - x3) - y1
= 4( 3 - 2 ) - 2 = 2
つまり、答えは (2, 2) であり、「さりり」と「たわわ」を足すと「きりり」になることが分かる。
同様に、上記11要素が、ここで定義した演算に対して閉じていることは、スクリプトを使って簡単に確認できる。 まさに瓶詰演算と呼ぶべきであろう。
あるる + あるる = きりり, あるる + あれれ = 無限遠点, あるる + きりり = ならら, あるる + きろろ = あれれ, あるる + さりり = なわわ, あるる + さろろ = たらら, あるる + たらら = たわわ, あるる + たわわ = さりり, あるる + ならら = さろろ, あるる + なわわ = きろろ, あれれ + あるる = 無限遠点, あれれ + あれれ = きろろ, ...
群(実は可換群)になることを示すのは技術的には難しくないが退屈なので省略する。 位数が素数だから巡回群であり、しかもどの元からでも全要素を生成できる。 例えば「あるる」から全要素を生成してみせよう。
あるる×1 = あるる あるる×2 = あるる + あるる = きりり あるる×3 = きりり + あるる = ならら あるる×4 = ならら + あるる = さろろ あるる×5 = さろろ + あるる = たらら あるる×6 = たらら + あるる = たわわ あるる×7 = たわわ + あるる = さりり ... あるる×11 = あれれ + あるる = 無限遠点
したがって、RSA暗号のときと同様に、ここでも「底」を固定して離散対数のようなものを考えることができるし、
繰り返し二乗法で計算量を節約することもできるだろう。
log あるる さりり = 7
もし、「あるるを7乗すればさりり」という計算が比較的簡単で、かつ、「あるるを何乗すればさりりになるか?」という逆算が難しいとするなら、 そこにも素数のべきの離散対数問題と類似の問題が存在して、計算量的な一方向関数を構成できる可能性がある。
「離散対数」という一般的用語に合わせてあたかも「累乗」のように表現しているが、
可換群で演算を加法的に書いているので、そっちにあわせるなら本当は「離散除法」というべきである。仮に
あるる×7 = さりり
を高速に計算する方法があるとして、かつ、
さりり÷あるる = 7
が計算量的に難しいとすれば……ということだ。
楕円曲線暗号。「曲線」そのものがどうこうというより、 楕円曲線の上の点と点のあいだにある方法で演算を定義して、それが群になって、 その群が、RSA暗号での剰余類の群みたいな役割を果たす……という二段構えが、 なじみの深い整数や因数分解に基礎を置くRSAより難しそうですが、 ちょっとおもしろそうな世界だと思いませんか?
Freeme.zip によると、 Microsoft Digital Rights Management (MS-DRM) V.2 で用いられている楕円曲線暗号は次の構成だそうです。
「楕円曲線の点の群の例」では、 非常に小さな有限群の上で、 楕円曲線の点の「掛け算」のイメージを示した。 もうほんの少しだけ規模を大きくして、実験を続けてみよう。
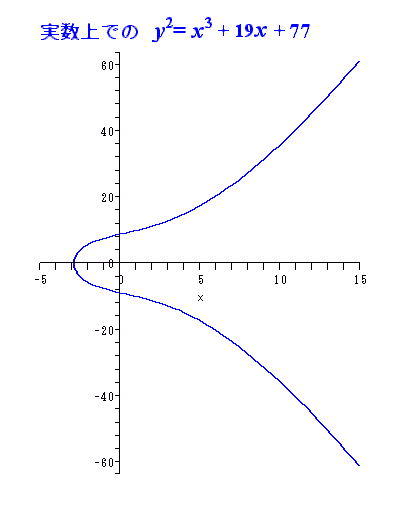
307は素数である。
ℤ307上の楕円曲線:
y2 = x3 + 19x + 77
を考える。
この曲線上の331個(素数個)の点は、
しらみつぶしに数えることができる。
(331個という数は、下記の方法であらかじめ下調べした。)
楕円曲線の式の形から、(x ,y) が曲線上にあれば、 (x, -y) も曲線上にあり、点を1つ発見するごとに実際には2つの点が見つかる。 (ただし、y = 0 の場合、y と -y は等しいので、これを重複して数えてはいけない。) x の捜索範囲は 0 から mod-1 をわたるが、y の捜索範囲は 0 から mod/2 までで十分だ。 上記のように±同時に点を見つけるので、mod/2 まで探すと実質的に -mod/2 から +mod/2 まで探したことになり、 0 から mod まで探したのと同じことになるからだ。
331個の点の座標を表す文字列に、Point[ 0 ], Point[ 1 ], ... というふうに、Point[ index ] ( index = 0...330 ) の形でインデックスをつける。 このインデックスの付け方には本質的な意味はなく、重複なく全部の点に1つずつ番号をつけておけばそれでよい。
var mod = 307;
var a = 19;
var b = 77;
var Point = new Array();
var index = 0;
Point[ index ] = "(0, 0)";
for(var x = 0; x < mod; x++ ) {
for(var y = 0; y < mod/2; y++ ) {
var L = ( y*y ) % mod;
var R = ( x*x*x + a*x + b ) % mod;
if( L === R ) {
var sPoint = "(" + x + ", " + y + ")";
Point[ ++index ] = sPoint;
if( y !== 0 ) {
sPoint = "(" + x + ", " + (mod-y) + ")";
Point[ ++index ] = sPoint;
}
break;
}
}
}
_debug("Point.lenght = " + Point.length);
document.write( "<p>" );
for(var i=0; i<Point.length; i++) {
document.write( "<strong>P<sub>" + i + "<\/sub><\/strong> = " + Point[i] );
if(i < Point.length-1 ) document.write( ", " );
}
document.write( "<\/p>" );
function _debug( str ) {
document.write( "<p>Debug: " + str + "<\/p>");
}
P0 = (0, 0), P1 = (0, 153), P2 = (0, 154), P3 = (1, 149), P4 = (1, 158),
P5 = (6, 10), P6 = (6, 297), P7 = (7, 89), P8 = (7, 218),
...
P329 = (302, 85), P330 = (302, 222)
(0, 0) はこの曲線上にないが、便宜上、無限遠点のこととする。
次に、この331個の点の間に加法を行う関数を書き下す。 小さい群なので、とりあえず全部の要素を明示的に書いてしまおう。 ここでは途中を省略しているが、実際には、 配列 Point には、上記のコードで生成した331個の座標値がべたで書いてある。
var Order = 331;
var Point = [ "(0, 0)", "(0, 153)", "(0, 154)", "(1, 149)", "(1, 158)", "(6, 10)", "(6, 297)",
... , "(302, 85)", "(302, 222)" ];
var ECCPoint = new Object();
for(var i=0; i<Order; i++ ) {
ECCPoint[ Point[i] ] = i;
ECCPoint[i] = new Object();
ECCPoint[i].index = i;
ECCPoint[i].coord = Point[i];
if( Point[i].match(/^\((\d+), (\d+)\)$/) ) {
ECCPoint[i].x = parseInt( RegExp.$1 );
ECCPoint[i].y = parseInt( RegExp.$2 );
} else {
_debug("ECCPoint: Init Error: " + Point[i] );
break;
}
}
function fairy_add( index1, index2 ) {
index1 = reduce( index1, Order );
index2 = reduce( index2, Order );
if(index1 === 0 ) return index2;
else if(index2 === 0 ) return index1;
var x1 = ECCPoint[index1].x;
var y1 = ECCPoint[index1].y;
var x2 = ECCPoint[index2].x;
var y2 = ECCPoint[index2].y;
if( x1 === x2 && y1 !== y2 ) {
if( (y1+y2) % mod === 0 ) return 0;
_debug("fairy_add: Something is wrong:"
+ ECCPoint[index1].coord + " : " + ECCPoint[index2].coord );
return void 0;
}
var lambda;
if( x1 === x2 && y1 === y2 ) {
if( ( 2 * y1 ) % mod === 0 ) return 0;
else lambda = ( 3*x1*x1 + a ) * rev( 2 * y1 );
} else {
lambda = ( y2 - y1 ) * rev( x2 - x1 );
}
lambda %= mod;
var x3 = lambda*lambda - x1 - x2;
var y3 = lambda * (x1-x3) - y1;
x3 = reduce( x3, mod );
y3 = reduce( y3, mod );
var sPoint = "(" + x3 + ", " + y3 + ")";
if( ECCPoint[ sPoint ] === void 0 ) {
_debug( "fairy_add failed. Dump:"
+ x1 + "," + y1 + "; " + x2 + "," + y2 + "; " +x3 + ", " + y3 + " : lambda=" + lambda );
}
return ECCPoint[ sPoint ];
}
function reduce( N , Mod ) {
if( typeof N !== "number" ) {
_debug("reduce: " + N + " is " + typeof N );
return void 0;
}
if( N >= 0 ) return N % Mod;
var k = Math.floor( Math.abs( N ) / Mod );
return ( N + Mod*(k+1) ) % Mod;
}
function rev( N ) {
if( typeof N !== "number" ) {
_debug("rev: " + N + " is " + typeof N );
return void 0;
}
if( N % mod === 0 ) {
_debug("rev: Bad input:" + N );
return void 0;
}
N = reduce( N, mod );
for( var i = 1; i < mod; i++ ) {
if( N * i % mod === 1 ) return i;
}
_debug( "rev: failed for: " + N );
return void 0;
}
点の足し算 fairy_add が定義されたので、 それを繰り返すことで、点を定数倍することができる。 ここでは規模が小さいので、100倍したければ100回足せばいい、という考えでやっておく。
function fairy_mul( index, N ) {
if( N === 0 ) return 0;
else if( N === 1 ) return index;
var result = index;
for( var i=2; i<=N; i++ ) {
result = fairy_add( result, index );
}
return result;
}
これで実演の道具はそろった。
ここですべての点を明示的に書き下したのは、 対象についての理解と実験を容易にするだけのためで、 技術的には全部の点をあらかじめ調べあげる必要はないし、 位数が大きければ、それはできない相談でもある。
アリスとボブは、このシステムについて合意している。 ハッカーは二人の通信を監視している。
まずアリスは楕円曲線上の点を勝手に一つ選んで、ボブに通知する。
ハッカーもこれを傍受できる。Point[8] すなわち:
P8 = (7, 218)
を選んだと仮定する。まわりくどい言葉遣いを避けるために、以下、この点を簡単に「点8」と呼ぶ。
以下の鍵交換は、発想は古典的な Diffie-Hellman 方式 そのものなのだが、 ただ、計算を楕円曲線上の掛け算で行うのである。
アリスは秘密の係数を選ぶ。 例えば75を選んだとする。 この係数は送信する必要ないので、ハッカーからは見えない。 アリスがやるのは、さきほどの「合意した点8」に秘密の係数をかけた結果をボブに送ることである。 点8を75倍すると、点26になる。これをボブに通知する。 ハッカーもこれを傍受できる。
ボブはボブで自分用に秘密の係数を選ぶ。 例えば234を選んだとする。 この係数はアリスにすら秘密にするので、ハッカーからは見えない。 ボブがやるのは、「合意した点8」に自分の秘密の係数をかけた結果をアリスに送ることである。 点8を234倍すると、点178になる。
アリスはボブから届いた点178に自分の秘密係数75をかける。
ボブはアリスから届いた点26に自分の秘密係数234をかける。
ふたりとも同じ点
P217 = (199, 151) を得る。
どういうことかというと、アリスの秘密を α、
ボブの秘密を β とした場合、アリス→ボブは
α (7, 218)
を送り、
ボブ→アリスは
β (7, 218)
を送る。
それぞれ、届いたものに自分の秘密をかければ、ふたりとも同じ
α β (7, 218) = (199, 151)
を秘密裏に、かつ公然と、交換できる。(下記のデモ参照)
α (7, 218)を β 倍するのも、 β (7, 218)を α 倍するのも容易だから、 アリスもボブも容易に最終的な結果を得られるが、 これを傍受しているハッカーは、同じ計算を行うために、 まずα (7, 218)を (7, 218) で「割り算」して、 アリスが使った係数 α を逆算する必要がある。 掛け算は容易だが、逆算は大変なのだ。
var PubPointIndex = 8;
_debug("PubPoint: P" + PubPointIndex + " = " + Point[PubPointIndex]);
var SecKeyAlice = 75;
var MaskedKeyAlice = fairy_mul( PubPointIndex, SecKeyAlice );
var SecKeyBob = 234;
var MaskedKeyBob = fairy_mul( PubPointIndex, SecKeyBob );
_debug("MaskedKeyAlice: P" + MaskedKeyAlice + " = " + Point[MaskedKeyAlice]);
_debug("MaskedKeyBob: P" + MaskedKeyBob + " = " + Point[MaskedKeyBob]);
var KeyByAlice = fairy_mul( MaskedKeyBob, SecKeyAlice );
var KeyByBob = fairy_mul( MaskedKeyAlice, SecKeyBob );
_debug("KeyByAlice: P" + KeyByAlice + " = " + Point[KeyByAlice]);
_debug("KeyByBob: P" + KeyByBob + " = " + Point[KeyByBob]);
/*
Debug: PubPoint: P8 = (7, 218)
Debug: MaskedKeyAlice: P26 = (20, 274)
Debug: MaskedKeyBob: P178 = (162, 225)
Debug: KeyByAlice: P217 = (199, 151)
Debug: KeyByBob: P217 = (199, 151)
*/
このシステムに挑むハッカーは、使用されている楕円曲線の構成、
その曲線上の合意された点8、マスクされたアリスの点26、マスクされたボブの点178の3つのデータを傍受している。
二人が秘密に交換した鍵を解析するには、fairy_mul を逆算する必要がある。
すなわち、
MaskedKeyAlice = fairy_mul( PubPointIndex, SecKeyAlice )
ということは、
26 = fairy_mul( 8, SecKeyAlice )
を意味しているから、「この群では点8を何倍したら点26になるか」を逆算すれば良いのである。
これを行う最も原始的な攻撃は次のようになるだろう。つまり、合意の点を2倍、3倍、4倍……していって、アリスが送信した点26が出る場所を探す。
それは75倍で発見される。アリスの秘密係数75がわかれば、それをボブから傍受した点54にかけることで(つまりアリスが行った正規の操作を繰り返すことで)、
ふたりの間でやりとりされたものを復元できる。
var test = 8;
for( var i=2; i<Order; i++ ) {
test = fairy_add( test , 8 );
if( 26 === test ) {
_debug("Cracked: SecKeyAlice = " + i );
break;
}
}
// Debug: Cracked: SecKeyAlice = 75
ここで使っているサンプルでは、そもそも fairy_mul 自体がこのような原始的な fairy_add の繰り返しで実装されているので、 ハッカーの計算量はアリスの計算量と変わらない。 しかし、数が巨大になると(例えば10桁とか100桁)、ひとつずつ可能性を調べる方法では時間がかかりすぎる。 一方、fairy_mul のほうは、係数を二進展開して繰り返し二乗法を用いれば、 巨大な数に対しても劇的に高速化できるはずだ。 もしハッカーに可能な攻撃が上記のような「遅い」ものだけだとするなら、 これは素数のべき乗の離散対数とよく似た、一方向関数と考えられる。
この方法を少し変えることで、鍵交換ではなく、メッセージ交換に使うこともできる(ElGamel暗号)。
楕円曲線暗号の価値はどこにあるのだろうか。 素数 p に対して、 ℤp はたった一つの世界だが、 その上に乗る楕円曲線は無数にあるから、群の選択の可能性がはるかに広い。 これは暗号リソースの豊かさを意味するし、古典的な数論的暗号よりも(多様なので)ある意味、難しいといえるだろう。 難しいということは、基本的には、暗号がクラックされにくいということにつながる。 実際、RSAのような素因数分解の難しさに依存する暗号は、 素因数分解に使えるCPUリソースとアルゴリズムの進歩につれて、前より安全でなくなってきつつある。 100桁程度の数の素因数分解は、ちょっと前なら事実上不可能と言われていたのだが、 今ではそうでもなくなってきている。 もちろん多項式時間では解けないのだが、それにかなり近づいている。
楕円曲線の離散対数問題は、今のところ、定量的に、もっと計算量が大きい。 同じオーダーの巨大整数を使っているとすると、 現在のアルゴリズムでは、楕円曲線のほうが、クラックしにくい=暗号強度が高い。 実質的に、より短い鍵の長さで、RSAと同じ強度を達成できることになる。 同じコストでもっと強力にできる、ということだ。
「楕円曲線暗号の強力さ」については、「本当に難しいから難しい=安全」と安心していいのかどうか、 それは誰にも分からない。 素数のべき乗の離散対数より「本質的」に難しいのか、 それとも、うまいアルゴリズムが作れるけれど発見されていないだけなのか。 突然すごいアルゴリズムが発見されて話が変わってこないか? という心配は、 どちらかといえば、 新しい楕円曲線暗号の方が大きいだろう。 実用的には、 暗号化して送信したクレジットカード番号が傍受されていて10年後にアルゴリズムの発達でクラックされてしまったとしても、 あまり問題ないともいえる。
秘密鍵の桁数の増加に対する処理に必要な時間コストの増加は、 正規のユーザにとってはゆるやかだが、 暗号をクラックしようとするハッカーにとっては急激であることを、実演する。 デモのために、JavaScriptで、鍵交換を行うための小さな楕円曲線暗号系を実装し、 正規ユーザの作業と、ハッカーの作業をそれぞれシミュレートする。
| 鍵の長さ(10進) | 正規ユーザ二人分の計算量 | ハッカーの計算量 |
|---|---|---|
| 2桁 | 10 | 10 |
| 3桁 | 20 | 100 |
| 4桁 | 20 | 380 |
| 5桁 (~10000) | 30 | 9995 |
| 5桁 (~50000) | 40 | 20900 |
| 6桁 (~100000) | 40 | 44194 |
| 7桁 (~1000000) | 61 | 502573 |
| 7桁 (~5000000) | 70 | 推定値 1000000 |
「楕円曲線暗号を用いた鍵交換」では、位数331の小さな群を使い、 テストのため、全部の点を書き出した。 今回は、位数1033の群を使い、「合意の点」以外の点は、必要になって初めて計算する。
秘密の係数を知っている正規のユーザとハッカーで、計算速度に差がつくことを実証するため、 今回は点にスカラーを掛けるとき、繰り返し二乗法を使う。 小さいといっても位数が1000を超えるので、 逆元の計算はbruteではなく、拡張ユークリッドを使う。
パラメータは次のとおり。
とりあえず無限遠点はデータ上 (0, 0) としておく。
function ECCPoint( x , y ) {
this.x = reduce( x , modulus );
this.y = reduce( y , modulus );
this.coord = "(" + this.x + ", " + this.y + ")";
}
var _O_ = new ECCPoint(0, 0);
ECCPoint.prototype.isO = function() {
return (this.x === 0 && this.y === 0)? true : false;
}
ECCPoint.prototype.toString = function() {
return this.coord;
}
ECCPoint.prototype.multiplied = function( k ) {
k = reduce( k , order );
var bin_str = k.toString(2);
var rev_str = "";
for(var n= bin_str.length - 1; n >= 0; n-- ) {
rev_str += bin_str.charAt( n );
}
var Result = ( rev_str.charAt(0) === "1" )? this : _O_;
var Work = new Array();
Work[0] = this;
for(var i=1; i<rev_str.length; i++) {
Work[i] = _add( Work[i-1] , Work[i-1] );
if( rev_str.charAt(i) === "1" ) {
Result = _add( Result, Work[i] );
}
}
return Result;
}
ここで、 reduce は、既約元──つまり 0 から (法-1) の範囲の代表元──への「正規化」を行う。 _add は2つの点を足す。
function _add( P1, P2 ) {
if( P1.isO() ) return P2;
else if( P2.isO() ) return P1;
var x1 = P1.x;
var y1 = P1.y;
var x2 = P2.x;
var y2 = P2.y;
if( x1 === x2 && y1 !== y2 ) {
if( (y1+y2) % modulus === 0 ) return _O_;
_debug("_add: Something is wrong:"
+ P1 + " : " + P2 );
return void 0;
}
var lambda;
if( x1 === x2 && y1 === y2 ) {
if( ( 2 * y1 ) % modulus === 0 ) return _O_;
else lambda = ( 3*x1*x1 + a ) * reverse( 2 * y1 );
} else {
lambda = ( y2 - y1 ) * reverse( x2 - x1 );
}
lambda %= modulus;
var x3 = lambda*lambda - x1 - x2;
var y3 = lambda * (x1-x3) - y1;
x3 = reduce( x3, modulus );
y3 = reduce( y3, modulus );
var P3 = new ECCPoint( x3 , y3 );
return P3;
}
このとき逆元 reverse の計算が必要なので、ユークリッドの互除法を拡張した次のアルゴリズムを使う。
function reverse( N ) {
var r = [ modulus, reduce( N, modulus ) ];
var q = [ 0, 0 ];
var x = [ 1, 0 ];
var y = [ 0, 1 ];
for(var i=2; i<100; i++) {
r[i] = r[i-2] % r[i-1];
if( r[i] === 0 ) {
return reduce( y[i-1] , modulus );
} else {
q[i] = ( r[i-2] - r[i] ) / r[i-1];
x[i] = x[i-2] - q[i] * x[i-1];
y[i] = y[i-2] - q[i] * y[i-1];
}
}
}
繰り返し二乗法でも、拡張ユークリッドでも、関数の呼び出しが終わるまで、使用済みの古い変数を解放しない。 本当は、だらだらと長い配列にする必要はなく、 繰り返し二乗法なら1世代前、拡張ユークリッドなら2世代前の数値を記録していれば十分なのだが、 ここでは、たかだか1000くらいの数の計算なので、メモリを節約するメリットがない。
http://www.faireal.net/demo/ecc2
JavaScript上でかなり強力な(説明用の例というより、実際に使えるほどの)RSAを構築できることは既に示したが、 同様に、巨大整数計算用のライブラリと組み合わせて、JavaScript上にかなり強力な楕円曲線暗号を構築することもできるだろう。 楕円曲線暗号の性質上、おそらく、RSAと同等の強度でより高速なものになると思われる。
実際に今回やってみて感じたのは、都合のいい曲線を見つける初期設定で時間がかかる、ということだ。 RSAでも鍵を作る部分で選んだ数の素数性を検証するのにいちばん時間がかかるが、それと感じが似ていて、 使用する曲線を決める部分で、選んだ群の位数が素数かどうかを検証するのに時間がかかる。
群が素数位数であることさえ確認できてしまえば、無限遠点以外の任意の点が生成元となるから、いちおう安心して「底」として使える。 現在の鍵長、10進4桁で処理に1秒もかからないうえ、鍵を長くしても(正規ユーザの)処理コストはゆるやかに増加することが見て取れるから、 その意味では、まだまだ先へ進める。けれども、都合良く位数が素数になってくれる設定を見つけるのは、10進4桁でもけっこう大変だった。 4桁の整数が素数か素数でないかそれ自体を調べるのは一瞬であるが、 選んだ群の位数が素数か素数でないかを決めるには、まず群の位数を決めなければならず、 現在の総当り的に可能な組み合わせをすべて調べて点の数を突き止める方法では、有限体の要素が1000程度でも、 点の可能性は1000×1000で100万程度あるからだ。 基礎となる有限体の位数を1万程度にした場合、1億オーダーの座標をすべて調べる原始的な方法では、破綻するだろう。 点の数は(基礎となる群の位数とだいたい同じで)1万前後になるが、 曲線のパラメータを少しずつ変化させたとき、 点の数の変化はかなりランダムで、偶数も奇数もあるので、うまいこと素数にあたってくれる可能性はかなり低い。
ふと気付いたのだが、楕円曲線の点の群(必ずしも素数位数とは限らない)を固定して、 任意の点を選んだ場合、その点自身の位数は群の位数を割り切らなければならない。 また、群が素数位数ならば、任意の元が生成元になる。 すると、位数が素数でない元や、位数が「小さすぎる」元が一つでも見つかったり、 または、位数の異なる2つの元が見つかった場合、 その群は素数位数でないと断定できる。 この考え方で、楕円曲線の点の素数位数の群を「確率的」に発見できるのでないかと予想できる。
素数位数の群を「良い群」と呼ぶとすると、「良くない群」は十分に小さい位数の要素を含んでいることから、 それと分かる。非常に大きな群について、 多くの要素を調べても、例えば100以下の素数の位数になっているものがないなら、 それはたぶん「良い群」であり、そうでなければ、絶対に「良くない群」である。 なかには、ちょうど素数性テストにおける擬素数のように、 多くの要素についてテストしてもたぶん「良い群」に見える「擬素群」もあるかもしれない。
非常に小さくはないが、非常に大きくはない群においては、Hassse-Weilの不等式が示す(可能な位数の)範囲に含まれる全部の素数についてチェックすることで、 それが「良い群」であることを決定的に証明できる可能性がある。例えば、pi (i=1, 2, ..., n) をそのような素数であるとして、 調べたい群から任意に一つの要素を取り出して、 その要素を各 i についても pi 倍してみる。 どれかの i について、 pi 倍した結果が無限遠点になれば、その瞬間に「良い群」と分かる。 さもなければ、それは「良い群」ではない。10万オーダーくらいは、JavaScript でも、これでいけるのでないか。 少なくとも、これまでの「点を枚挙する」方法よりは良さそうだ。
JavaScript で小さな楕円曲線暗号を実装する遊びを続けよう。
以下では 10進5桁の法 10007 と 位数 10091 (素数)を持つ楕円曲線暗号系を構成する。 Mozilla の上で(注: Mozilla の JavaScript は遅い)正規のユーザは、この暗号系を10ミリ秒オーダーの処理時間で利用できるが、 brute attack を行う攻撃者は10000ミリ秒オーダーのコストを要求される。
さらに、構成過程は明示しないが、 10進6桁の法 100493 と位数 100673 (素数)を持つ系でも実演を行う。 正規ユーザの計算量はほとんど変わらないのに対して、 brute attack で攻撃すると、1分近くかかる。
2桁、3桁、4桁の鍵長についての前回の実験と合わせると、 おおざっぱに10進10桁でクラックは困難になり、20桁程度で一応の実用強度に達すると予想される。 うわさどおり、RSAより短い鍵長で同等の暗号強度を実現できそうだ、という実感がわく。 もちろんJavaScriptではもともと遅いということもあるが、 比較の対象とするRSAもJavaScript上で構築したのだから、 この比較は合理的だ。
10進5桁のオーダーでは、以下の方法が効果的だった。
まず、その上に楕円曲線をはわせる有限体の法を決めてしまう。ここでは素数10007を選んだ。 10進5桁の最小の素数である。あとは、楕円曲線の定義式を少しずつ変化させて、位数が素数になるようにすればよい。 具体的には、次のようにした。
C : y2 = x3 + 9973x + B (mod 10007)
とおいて、1次の係数 9973 (勝手に選んだ)も固定してしまう。この楕円曲線 C の点の数は、
Hasse(-Weil)の定理によって、
(10007 + 1) ± 2(10007)1/2
の範囲にある。9807.93以上、10208.07以下である。
位数が素数になるとしたら、C上の無限遠点以外の任意の点をその素数倍したとき、結果は無限遠点となるわけだが、 この素数は上記の範囲になければならないから、具体的には次のいずれかだ:
var MyPrimes = [
9811, 9817, 9829, 9833, 9839, 9851, 9857, 9859, 9871, 9883,
9887, 9901, 9907, 9923, 9929, 9931, 9941, 9949, 9967, 9973,
10007, 10009, 10037, 10039, 10061, 10067, 10069, 10079, 10091, 10093,
10099, 10103, 10111, 10133, 10139, 10141, 10151, 10159, 10163, 10169,
10177, 10181, 10193
];
ゆえに、無限遠点以外の C の勝手な元を一つ選んで、 どれかの i について MyPrimes[i] 倍して無限遠点が得られたなら、 それが、望む位数である。 逆に、そのような結果を生じさせる素数が MyPrimes リストにないなら、 その群の位数は、素数ではない。 なぜなら、位数は9807.93以上、10208.07以下であることが保証されているが、 その範囲の素数についてすべての可能性が潰れたなら、結局、(有限体の)位数はその範囲にあるどれかの非素数ということになるからだ(選んだ元自身の位数は、それと等しいか、またはその約数)。 「ある元の位数は群の位数の約数」というLagrangeの定理──または、同じことだが「素数位数の群では、すべての元の位数が群の位数と同じ素数」という性質──に注意する。
例えば、 C の定数項を8000から8100へと変化させて、位数が素数になる場所がないか捜索するには、次のリストを使えばよい。
findPoint を使って点を一つ見つけて test と名づける。 C の右辺が平方剰余か非剰余かは恐らく確率50%ずつなので、 xを1以上100未満まで変化させるときの失敗確率は2-99であって、事実上、必ず点が見つかる。 次に、 test を MyPrimes[i] 倍して、どれかの i について無限遠点になったら成功であり、 それが望む位数である。どの i についても駄目だったら望むような曲線ではないから、C の定数項を変えて再試行する。
function ECC( a, b, modulus ) {
this.a = a;
this.b = b;
this.modulus = modulus;
}
ECC.prototype.findPoint = function( _x ) {
if( _x === void 0 ) {
for( var x = 1; x < 100 && x < this.modulus; x++ ) {
var oPoint = this.findPointAt( x );
if( oPoint !== void 0 ) return oPoint;
}
} else {
return this.findPointAt( _x );
}
}
ECC.prototype.findPointAt = function( _x ) {
var x = reduce( _x , this.modulus );
var X3 = ( x * x % this.modulus ) * x % this.modulus;
var AX = this.a * x % this.modulus;
var R = reduce( ( X3 + AX + this.b ), this.modulus );
for( var y=0; y < this.modulus / 2; y++ ) {
var L = reduce( y * y, this.modulus );
if( L === R ) {
return new ECCPoint( x , y );
}
}
return void 0;
}
ECC.prototype.getPrimeOrder = function() {
var test = this.findPoint();
for( var i=0; i<MyPrimes.length; i++ ) {
var Result = this.multiply( test, MyPrimes[i] );
if( Result.isO() ) {
return MyPrimes[i];
}
}
return void 0;
}
for(var B=8000; B<8100; B++ ) {
var objECC = new ECC( 9973, B, modulus );
var order = objECC.getPrimeOrder();
if( order === void 0 ) {
_debug( objECC + " is bad." );
} else {
_debug( objECC + " is good: order = " + order + " (prime)" );
break;
}
}
このオーダーの数だと、だいたい50試行に1回は、素数位数をもたらす曲線が見つかる。 1分もかからずに簡単に曲線が見つかるのである。 定数項を8000から8200に変化させるだけで次のようにいっぱい見つかり、よりどりみどりだ。
y^2 = x^3 + 9973 * x + 8044 (mod 10007) is good: order = 10141 (prime) y^2 = x^3 + 9973 * x + 8070 (mod 10007) is good: order = 10169 (prime) y^2 = x^3 + 9973 * x + 8100 (mod 10007) is good: order = 9887 (prime) y^2 = x^3 + 9973 * x + 8108 (mod 10007) is good: order = 10091 (prime) y^2 = x^3 + 9973 * x + 8142 (mod 10007) is good: order = 10111 (prime) y^2 = x^3 + 9973 * x + 8148 (mod 10007) is good: order = 9941 (prime) y^2 = x^3 + 9973 * x + 8179 (mod 10007) is good: order = 10093 (prime) y^2 = x^3 + 9973 * x + 8180 (mod 10007) is good: order = 9887 (prime) y^2 = x^3 + 9973 * x + 8191 (mod 10007) is good: order = 9941 (prime)
この例では、
y2 = x3 + 9973x + 8108 (mod 10007)
を選択した。
鍵交換を行う楕円曲線暗号系をこれで作るには、あとは曲線上の勝手な点を一つ選んで「合意の点」とすればよい。 使う曲線さえ決まれば、あとはたいした計算量ではない。 このデモでは、 (5755, 4233) を選択した。
注意: 正規利用者のシミュレーションは一瞬ですが、 暗号をクラックしようとする攻撃者のシミュレーションに数秒から数十秒かかる場合があります。
http://www.faireal.net/demo/libecc_0.1.js
http://www.faireal.net/demo/ecc3 (鍵 ~10000)
http://www.faireal.net/demo/ecc3a (鍵 ~50000)
http://www.faireal.net/demo/ecc3b_users (鍵 ~100000)正規ユーザのデモ(一瞬)
http://www.faireal.net/demo/ecc3b (鍵 ~100000)攻撃を行うデモ(時間がかかります)
10進3桁までの場合と異なり、実際に点を数え上げる方法では、10進4桁では時間がかかりすぎる。 例えば法が1万なら、もしかしたら曲線上にあるかもしれない、 という点の候補は1万×1万で1億もあり、仮に平均4分の1調べればよいとしても数千万の点を実際に調べることになって、 コストが大変だ。今回使った特定の元の位数を利用する方法だと、10進7桁くらいまではいけそうだ。 また、決まった点に、ある特定範囲のスカラーを繰り返しかけるのだから、そのたびごとに繰り返し二乗法を実行するのでなく、 1度だけ繰り返し二乗法で Work[i] を決めてしまったら、その曲線を調べ終わるまで、それを固定して使いまわすことでも、 少し計算量が節約できるはずだ。
いずれにしても、このオーダーでは、実際の楕円曲線暗号の運用自体はきわめて容易であり、 問題になるのは運用すべき楕円曲線のパラメータを決定する準備の部分なのである。
現在知られている攻撃法に対して、楕円曲線暗号(ECC)は、RSAより短い鍵の長さで同等の強度を実現できる。 言い換えれば、ECCは、RSAより少ないリソースで実装可能である。 したがって、RSAを実装可能な JavaScript に、ECCを実装できないわけがない。
JavaScript自身の整数型の限界である 253 より内側でさえ──つまり積をとってもオーバーフローしない最大26ビット程度(10進7桁)のパラメータでさえ──、 ざっとRSAの100ビットにも匹敵する強度を実現できる(RSA1024ビットがECC160ビットとされている)。 その場合、自力で無限精度演算を実装しなくて良いのだから、実装も容易であり、動作も速い。 JavaScript 自身の整数型の限界近くで、 手元の試験では、Mozilla の上で70ミリ秒で鍵交換を行える。0.1秒未満の一瞬だ。
「ECCの方がRSAより新しく高級だから、JavaScriptなんかでできるわけない」と錯覚しやすいが、 じつは、ある意味、ECCのほうが簡単なのだ。
ただし、ECCの設計と実装は、まるで話が別である。
ECCを設計するとは、そのシステムで使う楕円曲線の各パラメータを定義することである。 おおざっぱに言うなら、 楕円曲線上の点の数が素数になるように(または大きな素因数を含むように)、 有限体の上でうまく楕円曲線を定義することである。 本質的には、楕円曲線の上に乗る点の個数をどうやって数えるか、という問題だ。
現在、楕円曲線暗号系は、一般には、曲線パラメータがあらかじめ定義されて、ハードコーディングされている。 曲線を動的に生成するわけではなく、決まったひとつの曲線のうえで、100人なら100人のユーザが、鍵を動かす。 一般に、「決まったひとつの曲線」を定義する部分と、 曲線が決まってあとで、それを使って暗号通信を行う部分は、別だ。
うまい楕円曲線を見つけるところまではC言語などのより強力な手段を使って、 あとはそれをJavaScriptで運用する形にしても良いであろう。 しかし、10進7桁なら、まだ JavaScript 自身で設計もできる。 以下ではその方法を説明する。
繰り返し強調しておくが、このセクションで考えるのはECCの設計であって、 ECCの運用ではない。 次のセクションで実演するように、このサイズの楕円曲線暗号系の運用は、JavaScript でもきわめて容易であり、 さらにかなりサイズが大きくても容易であろう。 設計が大変だ、ということは、運用が大変だ、ということではない。
Schoof法、SEA法では、Hasseの定理の誤差項を直接決定するが、 そこまで大掛かりにしなくても、 10進7桁に対しては、10進5桁に対する方法を微修正することで、対応できる。
この方法ではさらなる前進は期待できず、無意味で不毛な袋小路の努力のようでもあるが、 意味などもともとない。 JavaScript をぎりぎりまで使い込む限界バトルそれ自体が目的なのだ。
非力な JavaScript でこの問題にいどむため、 まずは MyPrimes テーブルの両端を捨てて真ん中へんだけ残す。 Hasseの誤差項は0を中心に分布していて、最大誤差近くは薄いからである。 このことにより、実際には素数位数である「良い」系が、誤差がたまたま大きすぎたあまりに「悪い」と報告される可能性が出てくる。 本当は素数位数になっている myECC を一度は構成しながら、 「悪い」と誤判定して捨てる可能性はもったいない気もするが、 総合的にはこのほうが時間が節約できる可能性が高いのである。 探しても見つかる可能性が低いところは、最初から探さない、ということだ。 誤判定は常に「厳しめ」に発生するのであって、良いものを悪いと言うことはあっても、 悪いものが良いとされる可能性はない。
ただし、繰り返し二乗法で g_multiplyS_Work テーブルを生成する同じ手間で、 MyPrimes テーブルを総なめにできるので、 あまり両端を捨てすぎてはかえって損をする。 ぎりぎりの端は可能性が薄いので捨てていいと思う。
g_multiplyS_Work テーブルが従来の Work テーブルと違うのは、 g_multiplyS_Work はグローバル変数で一度計算したら使いまわせる、 という点である。せこい話だが、実効がある。 このテーブルを使うには、従来の multiply メソッドの代わりに、_multiplyS メソッドを呼び出す。 _multiplyS は上のグローバル・テーブルが空ではないとそれを使い、空ならば自分でテーブルを生成する。 だから、最初の呼び出しの前には、g_multiplyS_Work.length = 0 でテーブルをクリアすることと、 1回目の呼び出しのときにいちばん大きなスカラー倍を行い、テーブルを最後まで生成してしまうことが重要である。 これを怠ると、前回の計算で使った無関係な作業値を読んでしまったり、大きなスカラーをかけるとき必要な作業値が未定義だったり、 といった不都合が発生する。まあ、下線から始まるメソッドなど、そんなものだ。 MyPrimes テーブルで先頭にいちばん大きい素数が来ているのは、このトリックである。
次が最も本質的なトリックだ。
5桁のときのアルゴリズムを7桁に適用すると、
点を探すところでひどく待たされる。
MyPrimes[i] をかける作業より、点を探す作業がずっと長くなる。
そこで、
検索型の findPoint を使わずに点を自分で構成できるようにする。
使う点を x=0 に限定しよう。すると、
y2 = b (mod modulus)
の形になるから、b の平方根 β を直接求めれば、(0, β) は曲線上の点である。
これで findPoint の手間が一挙に省ける。ただし、b が平方剰余でない場合、
つまり上の二次式が解を持たない場合には、この方法では点を作れないので、点をスカラー倍する判定法が使えない。
いったんは良い曲線を選んでも、確率2分の1で判定不能になる。
しかしその場合に無駄になる時間は一瞬であるのに対して、
findPoint をしないことによる時間の節約は莫大なので、トータルでは、このほうがずっと良い。
このトリックがうまくいくためには、
modulus を ≡3 (mod 4) 型の素数にしておくと、つごうが良い。
1を足すと4で割り切れることを保証しておくのである。そうすれば、平方剰余である b に対しては、その平方根βを
β = ± b(modulus+1)/4
として、直接構成できる。このβの二乗は、確かに
b(modulus+1)/2 ≡ b(modulus-1)/2 × b ≡ b
である。b が平方剰余だからオイラーの規準によって、b(modulus-1)/2 = +1 だ。
ここで7桁の整数 b の大きなべき──指数は 7桁程度の整数である (modulus+1)/4 ──を7桁の法のもとで決めなければならない。 これは JavaScript 自身の組み込み関数ではできないから、RSAのときに用意した Bigint ライブラリを使う。 Bigint ライブラリは実装が手抜きで遅いのだが、とりあえず、この目的には使える。
もうひとつ必要なのが、b が平方剰余かどうか判定する関数である。 ヤコビ記号の計算をコーディングしてしまえばよいであろう。 ちょっと間違っているかもしれないが、だいたい次のようにできると思う。
function isQR(A, B) {
var sign = 1;
while(1) {
// (2/B)をくくりだす
var power = 0;
while( A % 2 === 0 ) {
A = A / 2;
power++;
}
if( power % 2 === 1 ) {
var test = B % 8;
if( test === 3 || test === 5) sign *= (-1);
}
if( A === 1 ) return (sign===1)? true : false;
// Aは奇数なので、ひっくり返す
old_A = A;
A = B;
B = old_A;
if( A % 4 === 3 && B % 4 === 3 ) sign *= (-1);
A %= B;
}
}
以上の方法を使った楕円曲線暗号系の設計作業は次のとおりであり、 2003年では型遅れである Pentium III 850MHz 程度のマシンでも、 10進7桁(約24ビット)のオーダーでは現実に実行できる。 JavaScriptで設計したこの規模の系は、すぐ後で例示する。
手元でやったときには、実際には a を素数(奇数)として、 b として偶数だけを選んだ。合理的な根拠はないのだが、 たまたま10進5桁のテストで、 a が素数だと b が偶数のほうが確率が高かったからだ。 それがたまたまで、素数位数をもたらす b の偶奇がランダムに分布しているとしても、 調べる場所が飛び飛びになるだけで、べつに損をするわけではない。
以上の方法で構成したのが、次の系である。
運用は、10進6桁でも7桁でも5桁と同様にできる。計算量もごくわずかに増加するが、ほとんど変わらない。 10ミリ秒のオーダーである。 しかし全数攻撃に要する時間は、16ビットで1分程度、20ビットで10分程度である。 上記の系は約23ビットであって、これまでの攻撃法でクラックするには、1時間くらいかかりそうだ。 RSAであれば、23ビットはJavaScript自身の試行除法であっという間に鍵が割れてしまう、ということを思えば、 ECCの強さが良く分かるだろう。 そのかわり、ECCはたった23ビットでも、構成に必要な計算量はばかにならない。
以下の実演では攻撃は行わず、正規ユーザの鍵交換だけを行う。計算時間は一瞬だ。
http://www.faireal.net/demo/ecc4_2
HTMLページから読み込んでいるライブラリは、ここにある。大きな間違いがあるかもしれないので注意。
http://www.faireal.net/demo/libecc_0.1a.js
以下のライブラリは運用には関係ない。 設計のとき、べき剰余を計算するのに Bigint.powmod を使っただけである。 このライブラリは特に割り算の実装がふまじめで、全体としてはあまり参考にならない。
http://www.faireal.net/demo/bigint_0_4c.js
追記: もう少しまともな bigint.js v0.5 の開発版。
http://www.faireal.net/demo/bigint0.5/
JavaScript で無限精度演算を簡易的に実装すること自体に興味があるかたは、こちらをみてください。 v0.4 より場合によっては数千倍も高速化されています。
くどいようだが、このメモで苦労したように書いているのは「ECCの設計」であって、 この程度の大きさなら、JavaScript上でECCを運用することそれ自体は造作ない。
たぶん、もっと暗号強度を強くしても、 運用のほうは快適であろう。2桁、3桁……7桁と鍵を伸ばしても10ミリ秒オーダーで桁数の一次式程度なので、 そのまま進めば10進10桁はせいぜい200ミリ秒である。 実際には8桁を超えると、積が 253 を超えてJavaScript自身の整数型には入らなくなるので、 無限精度演算を自力でやる必要があるが、 その手間を考えても、10進10桁くらいは1秒程度でできるのかもしれない。 (内部的には「整数型」ではなく倍精度のIEEE浮動小数点演算だが、 見かけ上、253 までは浮動小数点にcastされない。 つまり、シームレスに誤差のない整数演算を行える。 それを超えると精度が保証されない。)
ただし、そのような曲線をどうやって設計するかはまったくの別問題である。 位数がどうなってもいいのであれば、JavaScriptでも簡単に設計できるが、 位数をきっちり素数に落とすには、上の方法では、もう限界に近い。 すると、設計自体はJavaScript以外の方法を使う、というのが合理的な考えであり、 設計は別の方法を使ってもJavaScript上で運用することには(十分に速いのなら)一応の実用上の意味があると言える。
しかし、ここでやっていることは、もともと実用などというくだらない話ではなく、合理的ですらない。 非力な JavaScript でこれをやってしまうというばかげた話、 そのチープなスリルがすべてなのだから……。 JavaScriptでどうやって大きな楕円曲線の位数を数えられるのか、具体的なめどはまだない。 天下り的に曲線を与えられるのでも、与えられた曲線の点の数が実際に素数であることを検証することは JavaScript でできるので、 とりあえずは、そのくらいで満足すべきだろう。
JavaScript は53ビットなので、26.5ビットの二乗まではぎりぎりオーバーフローしないはずだ。
10進8桁の最後までは行けないが
226.5 = 94906265
までは、組み込み整数型でも行けるはずだ。
すでに23ビットに達しているので、
あと3ビット長くしてもなんぼのものだ、という感じだし、
その限界を超えられるように無限精度演算を自力で実装するのはさほど大変でないことも分かっている。
曲線の設計をJavaScript自身で行えるかどうかは別問題として、
もっと大きなECCをJavaScript上で運用することは、余裕で可能のはずだ。
JavaScriptだけを使って、 点の数が15桁(48ビット)の素数の楕円曲線を見つけることができる。
JavaScriptの数値型が整数解像度を保てるのは53ビットまでだから、 半分の26.5ビットまでの数は積をとってもオーバーフローしない。 法26.5ビット(~9490万: 8桁)までは、特別な配慮は要らない。 その先は任意精度演算を用いる。
libecc_0.2.js の
ECC.prototype.multi2 の実装では、
2数 a, b をそれぞれ下位7桁と上位に分解し、4回かけ算して繰り上がり処理などすることで、
最終的に結果の数値を文字列で取得している。
例えば14桁の2数をかければ28桁程度になる。
2^49 = 56294995 3421312
を下位3421312,
上位56294995 に分解した場合、
上位の二乗は
3169126462050025 であり、2の53乗:
9007199254740992
より十分に小さいから、49ビットの法では、
下位からの繰り上がりを考慮しても、この実装はオーバーフローしない。
50ビットではオーバーフローする。われわれの法は48ビット台だから、
この部分は変える必要がない。
一方、このようにして得られた strNumber を法で還元する演算において、法が14桁までなら比較的高速な
Bigint._mod_typeN を使えるが、
それ以上では、一般に Bigint._mod_typeF を使う必要がある。
しかし法15桁に限っては、高速化の余地がありここで
Bigint._mod_typeN_15
を導入した。割られる数を16桁ずつ区切って計算し、
その区切りが2の53乗:
9007199254740992
より小さい場合は、JavaScript 自身の剰余演算子を使う。
さもなければ(確率約10%)Bigintの剰余演算を行う。
われわれの被除数は30桁程度だから結局割り算は2回しか行わない。
var bigDivisor = new Bigint( nDivisor );
を定義しても、それを使い回せる確率は1%未満であり、まったく使わない確率が80%強であるから、
無駄になる。必要になった場合のみその場で new した方が速い。
従来のアルゴリズムより効率を上がられる場所が3か所ほどある。
法が大きくなると、ハッセの不等式の範囲に含まれる素数の個数は増える。 われわれの扱う範囲では、この素数のすべてまたは相当範囲を点の数候補とすることも可能だが、 そうすると巨大な配列を保持し続けることになり、 MSIEで顕著な速度低下が起こる。それよりも、ごく少数の素数を選んで小さい配列を作り、 そのぶんたくさんの b について調べたほうが結果的に速い。
この「選ばれた素数表」を作るときは、 次に述べるように二進展開で0が多い素数ほど良いのだが、 ただし、ハッセの広い範囲から0が非常に多い素数を探すより、 ごく狭い範囲で0が多めの素数を選ぶほうが手っ取り早い。 最小値と最大値が近いほうが後述する「共通部分」が長くなり効率が上がる。
二進展開が1の場所では、繰り返し二乗法で二乗の計算に加え「積」を計算するステップが入る。 二進展開が0の場所では、繰り返し二乗法では二乗をするだけで「積」は計算しない。 だから、二進展開に0が多ければ多いほど速く計算できる。 したがって、探したい素数位数は、二進展開して下位桁(非共通部分)に0が多いほど良い。
例えば、点にかけるスカラーの最小と最大が二進展開して
11101101001110110000001
11101101011111000010101
になったとしよう。上位約40%の
11101101000000000000000
は、どのスカラー倍でも共通だから、これを「くくり出して」使い回すことで、節約が考えられる。
すなわち、Point( 0, y ) に大きなスカラー q をかける代わりに、最初に共通因子をかけて共通の点 ComPoint を得ておき、 q から共通因子を引いた小さい因子をPointにかけ、結果の点と ComPoint を足せば最初の点を q 倍したことになる。
大きな法では素数の範囲をごく狭くすることで「共通部分」を長くし、効率を高めることができる。
2^32 より大きい最小の4n+3型素数は、
p = 4294967311
であり、二進展開すると0がたくさんある:
100000000000000000000000000001111
Fp 上の楕円曲線
C: y2 = x3 + ax + b
には、いくつの点があるだろうか。ハッセの式によれば、
p + 1 - 2√p ≦ #C( Fp ) ≦ p + 1 + 2√p
であるが、二進展開で1が少ないほうがいいことと、
点の数がハッセの不等式の範囲の両端に来ることは実際にはまれであることから、
とりあえず、
p ≦ q ≦ p + κ√p (0<κ≦1.0)
の範囲の q を考える。κ=1 のとき、この範囲にある素数は 2960 個である。
狭い範囲だけを高速に探すために κ=0.1 とすると、302個の素数が得られる。
最小 4294967311
最大 4294973843
二進展開すると
100000000000000000000000000001111
100000000000000000001100110010011
共通部分は上位20桁+13個の0の
100000000000000000000000000000000
非共通部分は13数字
0000000001111
1100110010011
この範囲の各素数をさらに吟味して、13数字のうち0が7個以上あるものだけを選ぶと結果は136個で、
最小 0000000001111
最大 1100100010101
この136要素の、二進展開した文字列を保持する配列を最初に用意する。
動的にやっても1秒かからない。
modulus = p, a = 1234567891 とし b = 0 から b をインクリメントさせながら、 その曲線上にある一つの点 Point( 0, y ) を計算し、 この点に上で考えている範囲の素数を順にかけて、どこかで無限遠点が出れば成功だ。 実際には素数を生でかけるのではなく、まず共通部分をかけて作業用の点 ComPoint を得ておき、 この点に「非共通部分を順次かけたもの」を足す。
b = 8597 で成功した。所要18分ほどだった。 成功するまでの計算時間の長短は、アルゴリズムの効率だけでなく運にも依存する。 アルゴリズム自体は、まだわずかに高速化の余地がある。
10万までの範囲の b を試したところ、3時間45分で21個の曲線を構成できた。 ひとつの曲線について、成功するまでの所要時間は1分未満から30分以上まで、ばらつきがある。 平均時間は10~11分だ。
y^2 = x^3 + 1234567891*x + 8597 y^2 = x^3 + 1234567891*x + 11903 y^2 = x^3 + 1234567891*x + 23974 y^2 = x^3 + 1234567891*x + 31053 y^2 = x^3 + 1234567891*x + 35026 y^2 = x^3 + 1234567891*x + 37486 y^2 = x^3 + 1234567891*x + 42492 y^2 = x^3 + 1234567891*x + 44270 y^2 = x^3 + 1234567891*x + 44953 y^2 = x^3 + 1234567891*x + 45287 y^2 = x^3 + 1234567891*x + 47245 y^2 = x^3 + 1234567891*x + 52523 y^2 = x^3 + 1234567891*x + 59224 y^2 = x^3 + 1234567891*x + 65031 y^2 = x^3 + 1234567891*x + 66005 y^2 = x^3 + 1234567891*x + 67177 y^2 = x^3 + 1234567891*x + 67624 y^2 = x^3 + 1234567891*x + 81887 y^2 = x^3 + 1234567891*x + 89594 y^2 = x^3 + 1234567891*x + 94354 y^2 = x^3 + 1234567891*x + 95490
完全には検証されていないが、同様な方法により、最高で法48ビットにいたるいくつかの曲線の生成に成功した。 以下は48ビットだ。
**** Prime Order *** y^2 = x^3 + 172358387239013*x + 200408220063094 (mod 281474976710731) Order = 281474976716851
この版は完成度が低いので注意。
スカラー倍するための最初の点を求めるとき、 従来は、a, b を与えて、その式を満たす (0,y) を求めていた。 しかし、例えば a を固定した後、その曲線上の一点 (1, y) を先に与えて、 曲線がその点を通るということから b を決めることもでき、 その方が速い。 従来のアルゴリズムと比べて、ヤコビ記号の計算、平方根の計算などが省略でき、 平方非剰余だったことで計算が無駄になることもない。
前回の例と同様のパラメータで、 今度は x を 1 に固定、y を 0 以上 50000 未満まで変化させることで、 同等の曲線捜索を行った(平方非剰余でスキップされることがないので、従来の方法で10万の b を調べたのと同等)。
結果、 3時間22分で17個の素数位数の曲線を検出できた。一つの曲線が見つかるまでの時間は、平均11.9分で、 19秒から33分までばらつきがある。たまたまいい曲線が見つかりにくい設定を選んでしまったようだが、 それにしても、純粋に「ひとつの曲線について吟味するコスト」を考えると、10%の高速化が認められた。
y^2 = x^3 + 1234567891*x + 3083410628 (mod 4294967311) y = 4797 Order = 4294970761 y^2 = x^3 + 1234567891*x + 3086338068 (mod 4294967311) y = 5093 Order = 4294968329 y^2 = x^3 + 1234567891*x + 3087180044 (mod 4294967311) y = 5175 Order = 4294967563 y^2 = x^3 + 1234567891*x + 3196845180 (mod 4294967311) y = 11681 Order = 4294967857 y^2 = x^3 + 1234567891*x + 3244625748 (mod 4294967311) y = 13573 Order = 4294968257 y^2 = x^3 + 1234567891*x + 3261103308 (mod 4294967311) y = 14167 Order = 4294969897 y^2 = x^3 + 1234567891*x + 3304383819 (mod 4294967311) y = 15620 Order = 4294971937 y^2 = x^3 + 1234567891*x + 3361907915 (mod 4294967311) y = 17364 Order = 4294968371 y^2 = x^3 + 1234567891*x + 3380201108 (mod 4294967311) y = 17883 Order = 4294969153 y^2 = x^3 + 1234567891*x + 3634385183 (mod 4294967311) y = 23958 Order = 4294969099 y^2 = x^3 + 1234567891*x + 3685499423 (mod 4294967311) y = 25002 Order = 4294973713 y^2 = x^3 + 1234567891*x + 3717193803 (mod 4294967311) y = 25628 Order = 4294968101 y^2 = x^3 + 1234567891*x + 3760478100 (mod 4294967311) y = 26459 Order = 4294968347 y^2 = x^3 + 1234567891*x + 4254862140 (mod 4294967311) y = 34561 Order = 4294972049 y^2 = x^3 + 1234567891*x + 4273458660 (mod 4294967311) y = 34829 Order = 4294971431 y^2 = x^3 + 1234567891*x + 295650032 (mod 4294967311) y = 39118 Order = 4294968583 y^2 = x^3 + 1234567891*x + 823596797 (mod 4294967311) y = 45367 Order = 4294968199
「さらなる多少の高速化: 32ビットで10%」の方法を使うと、 48ビットでも約2.5%の速度改善が見られた。改善率が32ビットの場合より低いのは、 この方法で改善されるのは「最初の点」を計算する部分で、その点を素数倍していく計算の部分は変わらず、 48ビットではその部分が長いからだ。
それでも2.5%改善されると、40時間のオーダーでまるまる1時間短縮される。 以下の曲線は、約16万5000個の可能性を調べて見つかった。 合計推定所要時間、41時間。
**** Prime Order *** C: y^2 = x^3 + 172358387239013*x + 109143813811721 (mod 281474976710731) A point on C: (1, 164998) Order = 281474976719683