RLM文字(HTMLでは ‏)は、書式方向「右から左」のゼロ幅文字だ(幅がゼロなので、書いてあっても目には見えない)。
これは書式方向制御文字(ここから「右から左」にしろ、というたぐい)ではない。
どういうときに使うのだろうか。
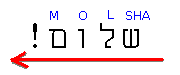
例えば、「こんにちは!」という意味のヘブライ語「シャローム!」の最後につける感嘆符(びっくりマーク)について考える。 SHAを表す ש U+05E9, Lを表す ל U+05DC, Oを表す ו U+05D5, Mを表す ם U+05DD をこの論理的順序で並べて、最後に感嘆符 U+0021 をつけるとする。
バイナリー (UTF-16 BE) 05 E9 05 DC 05 D5 05 DD 00 21
大域的な書式方向が左から右になっているなかにこのコードを書くと、期待通りの効果が得られないだろう。
![]()
ヘブライ文字の部分はちゃんと右から左につながるが、感嘆符がヘブライ語の行頭(いちばん右)に来てしまう。 パーサが間違っているというより、上のコードがそれだけでは、あいまいだからだ。
この現象は、双方向アルゴリズムが作用する境界があいまいなために発生する。 パーサは、左から右へ進む文字なかで、U+05E9 に出会う。 これはヘブライ語の文字で右から左に結合すべきことが定められているので、ここから「右から左」ブロックになる。 U+05DC, U+05D5, U+05DD まで4文字を読み込んだあと(ここまではヘブライ文字)、感嘆符を発見する。 感嘆符のあとでは、ふたたび左から右へ進む文字が並んでいる。 ――「右から左」ブロックの最初の文字が U+05E9 であること、 U+05DC, U+05D5, U+05DD までの4文字は「右から左」ブロックに属すること、 感嘆符より後ろが「左から右」ブロックに属することは、確定的だが、 感嘆符そのものがどちらのブロックに属するかが、ハッキリしない。 特殊扱いすべきブロックに属する証拠がないので、パーサは、感嘆符をデフォルト扱いするだろう。 つまり「右から左」ブロックに含めないようにするだろう。
感嘆符がどっちのブロックに属するのか、形式的に判断する方法はない。 例えば、「ヘブライ語のあいさつはシャローム! 覚えておけ」と言うとき、 「ヘブライ語のあいさつはシャローム」ということを力説しているのか、 それとも「シャローム!」の感嘆符まで含めて引用しているのかハッキリしない。
感嘆符でなく、ピリオドや疑問符のようなほかの句読点でも、同じことが起きる。 HTMLであれば、dir属性を使って方向を強制することもできるが、プレインテキストを含むUnicode一般では、 dir属性のような上位の制御が利用できるとは限らないから、HTMLのdir属性はユニコードのレイヤにおける本質的な解決法ではない。
言い換えれば、ヘブライ語の部分が感嘆符でまだ終わりでないことがハッキリしているなら、 パーサは迷わず感嘆符を「右から左」ブロックに含める。 実際、「シャローム! シャローム!」と2回、繰り返して書けば、1つめの感嘆符はヘブライ語の一部と認識され、 正しい位置にくる。観察しやすくするため、2つめの感嘆符を疑問符に変えて調べてみよう。 「シャローム! シャローム?」
![]()
感嘆符は期待通りの位置――ひとつめ(右側)のシャロームのうしろ(左)――に来るが、 疑問符は期待通りの位置――ふたつめ(左側)のシャロームのうしろ(左)――に来ないで、 見かけ上、ヘブライ語部分の行頭(いちばん右)に現れるだろう。 これは「シャローム! シャローム」でヘブライ語ブロックが終了して、「?」はヘブライ語ブロックに続く次のブロックに属すると認識されたためだ。
以上から分かるように、「シャローム」につづく句読点(感嘆符、疑問符、ピリオドなど)もヘブライ語の部分に属することを明示するには、 句読点がブロックの境目にならないよう、句読点のあとでも、まだまだ右から左へ進む文字が続いているようにすれば良い。 実際にヘブライ語文がまだまだ続いていれば、何もしなくても良い。 実際には「シャローム!」で終わりにしたい場合、ユニコード的解決法としては、 感嘆符のうしろに「見えないヘブライ文字」があるようにすれば良い。 これが幅なしRLM文字 U+200F であり、 ヘブライ語に限らず、アラビア語での同様な問題を解決するのに使うことができる。 幅なし(zero-width)なので、このコードポイントは論理的に(バイナリーで)のみ存在し、表示上は見えない。
バイナリー (UTF-16 BE) 05 E9 05 DC 05 D5 05 DD 00 21 20 0F
逆に、感嘆符がヘブライ語に属さないことを明示的に示す一つの方法として、 感嘆符の前に幅なしLRM文字 U+200E を置くことも考えられる。
RLM文字は、HTMLでは、‏ として参照することもできる。
<!ENTITY lrm CDATA "‎" -- left-to-right mark, U+200E NEW RFC 2070 --> <!ENTITY rlm CDATA "‏" -- right-to-left mark, U+200F NEW RFC 2070 -->
次の2つの例を比較せよ。
ユニコードで、日本語や英語の文字は「左から右に書く」という文字単位の強い属性を持っている。 また、ヘブライ語やアラビア語の文字は「右から左に書く」という文字単位の強い属性を持っている。 句読点、例えばピリオドは、「左から右に書く」言語と「右から左に書く」言語で共用できるように、 それ自身では強い書式方向属性を持たず、 環境に依存する。より具体的には、同一の強い書式方向属性をもつ文字に囲まれると、その属性を継承して、弱い書式方向属性をおびる。 弱い書式方向属性をおびた句読点類は、いっそうニュートラルな空白類のレイアウトに影響を与えることが可能だが、 強い書式方向属性がある文字に逆に影響を与えることはできない。 したがって、ある句読点の手前に「右左」文字、その句読点の直後に「左右」文字がある場合、 その句読点の書式方向属性は直前、直後のブロックからは等しく影響を受けるので、 より大きな全体の属性に依存するが、 もし句読点の手前に「右左」文字があり、その句読点の直後にさらに「右左」文字(幅なしでも良い)があるなら、 その句読点は、より上位レベルを調べるまでもなく、ローカルな前後の環境から「右左」属性を継承する。
Windows 2000 のメモ帳では、右クリックメニューから選ぶだけで、指定の場所にRLMほかを挿入できる(Microsoft Windows 2000 Professional ドキュメント)。 べんりな機能ではあるが、しょせんメモ帳なので、あまり使いやすくはない。
2003年3月現在、実際のヘブライ語圏のウェブページでは、dir属性を明示したりRLMを使うかわりに、 次のように「末尾に来る句読点を、あらかじめひっくり返しに書く(論理的な行頭に書く)」という妥協案で、 プレフォーマットされていることが多い。 (ヘブライ文字そのものをひっくり返しに書くわけでなく、パラグラフの最後の句読点のみ細工する。)
この方法は、 パラグラフ末尾の「行末の句読点」をソースでは「行頭」にタイプしなければならず不自然だが、 比較的に古いブラウザでも期待通りの表示が得られるだろう。
右から左へ書く言語と左から右へ書く言語の混在
ABC/Hidden Reference Audio Comparison Tool で [ABX] を実行すると、 ツールがランダムに「本物」か「圧縮音楽」かのどっちかをあなたに聴かせてくる。 あなたは「本物」か「圧縮」か判断して答を書き込む。 あとから成績が分かる。 だれかテストしてくれる人がいなくても、ひとりで簡単にブラインド・テストをできておもしろいので、 音質にこだわるかたは、いちど実行してみると良い。
アニメの効果音(戦闘機のエンジンの音)2~3秒をネタにやってみた。 「オリジナル」は、テレビからキャプチャーした48000HzのWAVファイルの無圧縮。 サンプル1は、オリジナルを -q 0 で約64Kbpsの Ogg Vorbis にして、WAVにデコードしたもの。 サンプル2は、サンプル1のVorbisとほぼ同じサイズになるようにオリジナルをlameで圧縮して(24000Hzでリサンプリングされる)、 ふたたびデコードしたもの。
オリジナルとサンプル1で聴き比べても、 オリジナルとサンプル2で聴き比べても、 ほぼ成績は同じで、繰り返してやると、たまーに(10回の1回くらい)脳がつかれるのか区別がつかなくなって誤答を出した。 完全にこれはこっち、と瞬時に区別がつくほどの違いではなかった。 では、mp3とvorbisは同じくらいの良さかというと、 このサンプルでは、vorbisの聴き比べのほうがハッキリ難しかった。 mp3だと、 「あ、これは圧縮して劣化してるな」「これは圧縮、これはオリジナル」という感じで、わりとぱっぱっと答えられるのだが (でもたまに間違う)、vorbisとオリジナルの聴き比べだと、「えーー? ほとんど同じじゃん? これ圧縮されてるの? しかも64……」という感じ。 よーく聞けば、結果的にはだいたい判別はつくのだが、実際問題、差を認識できないと思う(ふつう、 そんなふうにある場所の音を繰り返し何度も聞いたりしないし、オリジナルと対比して聴き比べもしないので)。 疲れていないときに、良い再生環境で、最高に集中してやれば、100%区別がつくかもしれないが、 一般的な環境のPCでふつうに聞く分にはそんなに差はない。 動画(OGMなど)の音声に使う場合、q 0 でやっても(オリジナルとじっくり聴き比べない限り)分からないだろうと思う。 これは戦闘機のエンジン音だから、繊細で複雑な音楽では、 またべつの判断になるかもしれないが、手元では、ふだんエンコードする動画は音楽クリップなどでなくアニメなので、 ノイズや人の声のような非音楽的な音のほうが多い。
よく(まるでCD音楽をMP3にするときみたいに)アニメでも「音声は128はほしい」とか漠然と言われて、 それがクオリティーへのコダワリのようにも言われるのだが、 実際にブラインドテストABX法で聴き比べてみると、64でも案外いけるかもしれない、と思った。 OPのような「音楽」だと64や80では差が出てしまう場合もあろうから、 べつべつにちがった音質でエンコードして、 あとからくっつける、というのも手かもしれないなぁ、などと考えている。
2003年3月19日 「ブラインド・テストで実感 MP3 vs. OGG Vorbis」で、実際に聴き比べるとOgg Vorbisの音質の良さが分かると書いた。 64Kbpsでもオリジナルに近い音質だったと報告したが、そこにも書いてあるようにサンプルは「エンジンの音」の効果音だった。 人の声を Oggenc -q 0 した場合には、感覚的に少しディテールが失われる感じがする。ABXでブラインドテストを行ったところ、 人がしゃべってる部分では、百発百中でオリジナルと容易に判別がつく。したがって、アニメや映画をOGMにするとき、観賞用では、Oggenc -q 0 は、おすすめできない。
それこそERRCHKではないが、現状、「映像部分が Huffyuv と区別がつく画質じゃいけない」ということはないし、 同様に、音声部分もオリジナルと完全等価である必要はない。場合によっては、-q 0 もありだろう。 だがファイルサイズなどで余裕があるなら、オリジナルにより近い音質にしておきたいのも当然だ。-q 1 よりは -q 2, あるいは場合によっては -q 5, それが無理でも、1.3 よりは 1.4, あるいは 1.45 というふうに、サイズ的に可能なら、 ちょっとでもオリジナルとの差を小さくしておいたほうが良いに決まっている……。言うまでもなく、 圧縮効率と音質のトレードオフがあり、損益分岐点がある。
OGMの日本語字幕SRTでつねづね思うのは、 各行末に大量にダミーのスペースを入れることでファイルサイズがムダに増大し、 その「損失」は、Oggenc の q 値で0.1オーダーに相当する、ということだ。バグを回避するためのばかげた空白、 本来必要ない無意味な部分にファイルサイズを食われるくらいなら、できれば音質や画質にまわしたい。 無意味なスペース挿入で、音質が何Kbpsか犠牲になっている、という見方をすると、なんだか不愉快になってくる。 (もちろん字幕が何トラックあるかにもよるが。)
実際にABX法のブラインドテストを行うと特に実感するが、人間の耳や目は意外と 8Kbps だの 2Kbps だのといったセコイ差で、 オリジナルと区別がつかなくなったり、「何か歪んでいる」と感じてみたりする。 閾値というのは、かなりビミョーなのだ(言い換えれば不合理――機械的に測定すれば、どっちにせよオリジナルとは激しく違うのだが)。 Vorbis 112Kbps ならオリジナルと区別がつかないのに、110Kbpsだと「あれ?」と思ったりするかもしれない。 1Kbpsを笑うものは1Kbpsに泣く……かもしれないのだ。 そしてまた、どこをとってもオリジナルと絶対に区別がつかないレベルの高音質を求めるオーディオマニアにとっては、 LAMEよりもMusePack(MPC)の192あたりが理想なのかもしれない。 LAME MP3 の128なら明らかにそれより高圧縮のVorbisのほうが良いだろうし、 LAMEの160超は(マニアに言わせれば)MusePackのほうが同サイズで高音質だという。 10年前には革新的発明だったかもしれないMP3という形式はもう引退時期で、極論すれば後方互換性のためだけに存在しているとさえ思える。 128より上の高ビットレートならMPC、128以下の低ビットレートなら Ogg Vorbis あるいは(フリーでなくてもいいなら)AACやMp3Pro?
2003年3月10日: わお、アフガニスタンの ccTLD
http://www.undp.org.af/
思い返せば、この .af が見たいのに見れなかったので、かわりにアフガンねたのページを作ったのでした・・・。
記念撮影

ここから新政府のもとで秩序あるなんたらという宣伝を流すのでしょうか。
Media Player Classic 6.4.3.1 UTF-8字幕サポート――日本語の字幕が簡単にふつうに埋め込めるようになる日も近い予感
高速化や不具合修正のほか、次世代字幕フォーマットUSFが Windows 98 でもテストされた。
どうやってか、OS自体がユニコードでないWin98 でも、utf-8, utf-16le, utf-16be を独自にサポート開始という。
MSXML.DLLを使ったUSFサポートは本家TCMPより良い。
手元の Win2K では双方向アルゴリズムが正しく動作するのを確認できた。
右から左へ進む言語を含む多言語混在テキストを字幕として完全に混在表示できる。
USF公式サイトにあるサンプル USFV100_sample.usf はソース自体のアラビア語がひっくり返しなので、テストには
USFV100_sample-Arabic-fixed.usf
を使うと良い。USFはUTF-8で書かなければならない(義務的)。
ユニコードの文字がどうにでも自由に使えるようにするため、USFをWinCPで記述することは禁止される。
ただし、字幕の設定ダイアログでは当面、自分の言語設定のデフォルトを選び、内部的に変換を行う。
あとはOGM/OGG/MCF/MKVのどのコンテナであれ、要はUSFをMUXできれば、 すぐにも日本語字幕は普通にできるようになる。再生側はとりあえず整った。
MPClassicでのUSFテストの仕方。
View | Options の Playbackタブの
Output | Video で、
VMR7(WinXP)またはVMR9(要DirectX9)を選ぶ。
Subtitles タブでフォント設定を念のため、
Arial Unicode MS のようなユニコード汎用フォントにしておく。
適当な軽いビデオを開く。
次に File | Load Subtitle でUSF字幕(今は外部)を開く。
サンプルUSFでは最初の一連のテストが終わったあとにユニコード対応テストがある。
MPClassicでのUSFサポートはMSXML.DLLに依存する。 TCMPのように自分でサポートしないぶん少し重い。
UTF-16のSRTも外部ファイルとしてなら正しくオープンできる。 BOMが必要。 UTF-8も同様に外部ならうまくいく。 ユニコードな埋め込みSRTはBOMがあってもなくても、うまくいかない。 MPClassicでうまく処理できる日本語(ユニコード)は、 外部からのUTF-8BOM/UTF-16BOMのSRT形式(ほぼプレインテキスト)と、 外部からのUSF形式(BOMは使わない。スタイリング可能)。
2003年3月11日 : MatroskaDub が更新されたので、いくつかMKVを作ってみた。
AVI 223,404KB MP3 VBR 22,695KB Direct Stream Copy - Save As: AVI 247 516KB (241.7MB) OGM 248 032KB (242.2MB) MKV 247 006KB (241.2MB) 238,929KB (233.3MB) AVI (MP3VBR) - Transmux Into: OGM 239,355 (233.7MB) MKV 238,423KB (232.8MB) 179,200KB (175.0 MB) AVI (MP3VBR) - Transmux Into: OGM 179,167KB (175.0MB) MKV 178,716KB (174.5MB) 81543KB (79.6MB) OGM (Vorbis) - Transmux Into: MKV 81324KB (79.4MB)
現段階ではWindows環境での再生が整ってないので、サイズの話しかできない。 250MBの大きなファイルで、AVIとの差は0.5MB、OGMとの差は1MB。 OGMとの差1MBはそれなりに大きいとしても、AVIとの差0.5MBは200MB台のなかでは、そんなに気にならないだろう。 多くの場合、どうでもいいことだ。 小さくなるのは確かだが……。 175MBクラスでの0.5MBの差は、場合によっては(ビットが不足気味のとき)、ちょっとおいしい。 96KBpsか80Kbpsかといって音をせこく削って何とかしのぐことを思えば、何もしないで0.5MB浮くのはうまい。 もともとサイズ的に余裕があるときには1MB未満の差は気にならないだろうが、 175MBだとあまり余裕がないことが多いからだ(サイズを小さくしたいから、でなく、絞り出せるなら画にまわしたいから。 ECFスクリプトで2パスをぎりぎりまでコントロールするような古くさいエンコーディングを知らないと、 何がうれしいのかピンとこないかもしれない)。 80MB程度の小さなOGMとの比較では0.2MBしか縮まなかった。 すべての例で確実に縮むが、差を大きいとみるか小さいとみるかは状況しだい。
OGMはファイルサイズという点では、あまりかんばしくなく、 AVIとほぼ同じか、少し大きくなっている。 空間効率の点でのMCF以来のMCF vs. OGGでのOGG批判は、根拠のある批判だったと言わなければならない。 しかし、AVI vs. MKVの空間効率比較では、MKVはAVIに確実に勝ってはいるものの、そんなに劇的な差があるわけでもない。 もちろん空間効率以外の点でもAVIには弱点があるが。
Linux環境では、すでにプレーヤーのMKV対応が可能になりはじめていてWindows環境でも時間の問題、 年内には字幕や何かの部分のサポートも順次、始まるのだろうが、 SUB字幕をラクにバックアップしたいとか、オーディオマニアで音声にMPC(Musepack)を使いたい、 といった明確な目的意識でもない限り、急いで乗り換えるメリットは少ないだろう。 少なくとも手元では、MKV自体の再生ができるようになっても、 USFサポートが始まるまでは、OGMから乗り換えることは不可能だ。 マルチサブは、OGMの場合同様、単一言語の日本語圏では、そんなにニーズがないだろうし、 日本に限らず、一般には、字幕のスタイルといっても、 フォントの種類や色を変えるといったむしろどうでもいいことしか思いつかない人も多いだろうから、 DVDでできることの範囲で満足できるユーザは、OGMのSRTで充分でないか。
こうしてOGM以外の選択肢が見え始めてくると、OGMがコンパクト、というのは、音声を Ogg Vorbis にすると高圧縮で高音質、というコーデックの話であって、OGG/OGMという格納形式それ自体がコンパクトという意味ではない、ということが、イヤでも実感される。 たとえ Ogg Theora + Ogg Vorbis であっても、OGG形式で合体させなければいけない、という義務はないからだ。
BT (BitTorrent) はクリックするだけで始まるが、処理ファイル数と同じだけのインシデントが発生する(最大9)。 例えば4つのファイルを処理するには4重に起動することになる(IEのダウンロード状況のダイアログボックスのようなものなので、 必ずしもじゃまではない)。BT++では1つのソフトで複数のダウンロードを管理できるが、BTと違ってクリックするだけでは動かない。 最初にトレントファイルを持っている必要がある(この感覚はちょっとFreenetのシードに似ている)。
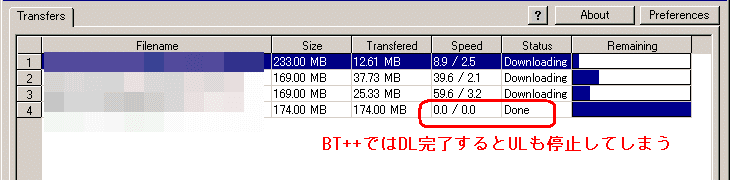
BTは、すでに持っているファイルに対して上書きDLを指示することで、簡単にアップ専用ノードとなることができる。 3.1-cvs-3プライベートビルドとして、速度をコントロールできるものも公開されている。 BT++ではダウンロードが終わったファイルはアップロードできないようだ。 アップ(というか中継)拠点として使うにはふべん。
BT++は要するにダウンロードマネージャー。ダウンローダーにはべんりだが、アップ拠点にはふべん。 すでにあるものを上書きふうにDLさせようとしても、ハッシュが合うと「完了」になってアップも動かない。
BT++の注意事項。ダウンロードリンクをクリックしてもすぐにリストに追加されるわけではない。 少し待つ。また、ダウンロードリンクをクリックする前に、対応するトレントファイルを指定パスに落としておかないと駄目なようだ。 (リンクを右クリックして保存しておけば良い。) 繰り返すが今のBT++は、BTのように「クリックするだけ」では正常に動かない。いずれも、 従来のナップ/ヌーテラ型のP2Pとはかなり発想が違って、むしろ根幹はサーバ・クライアントの昔の構図に近いのだが、 ただし、ダウンロードがぜんぶ直接中央につながらずに接続形態だけ分散になっている。 特にBT++は「落とし終わったものは全く共有せず、落とし中だけ中継を手伝う」という、ある意味、冷めた哲学でできている (落とし終わったノードが善意でさらに共有を続けてくれるなどと期待しない)。
BT/BT++は、ナップ、ヌーテラ、フリーネット系と直接比較するものでなく、 ある意味、SysResetと比較するのが適当だ。 SysReset でいう Voiced Only のシステムと似ていて、自分も何かしない人には落とさせない、ということ、 しかも、アップ帯域を出さないと比例してダウン帯域も来ない、というのは、昔なつかしいFTPのレートのようだ。 SysReset のように手軽に共有できないので、水平の立場でトレードしたりするのにはぜんぜん向かない。 BT/BT++は、水平というより、中央にいる「神」が効率的に吸わせたい、というシステムだ。 それ以外に意味があるとしたら、BT/BT++ではクライアント側はいっさい自分の意思でアップはしないので安全といえばまあ安全なのかもしれない。 そのぶん責任がトレントのおいてあるサーバに集中して、つぶしたい側からみると「責任者」を特定しやすい、といえるだろう。 それでも、特に++のつかないほうのBTはそうだが、最初のそもそもの発信者が落ちても、 トラッカーが動いていて有効な転送(シード)がある限り、タネが飛んだ先がまたタネになる、という感じで、 ファイルがそれ自体で勝手に広まりつづけることができる(このイメージはやっぱりFreenetに似ている)。
そしてファイルがそれ自体で勝手に広まれるということは、「人間が要らない」システム、人間を信じないシステムとも言える。 あなたが突然落ちたり、悪意でアップロードを中止しても、あなた経由で落としていたノードは少しも困らない。 さくっと分割ダウンのルーティングを変えるだけだ。 ファイルを捏造してもハッシュが合わないのですぐばれる。 人間のやることを信じない……。逆に落とす側からみれば、 よほどのことがない限り必ず待っていれば落ちきる。だいたい帯域なんてトータルでは余りまくっているうえ、 みんなつながってるのだから、もう誰が「所有」しているか、ということ自体そもそもなんか意味がなくなってきたような気もする。