Unicode 3.0 レベルのルーン文字の場合、Mozilla / MSIE どちらも好ましい反応
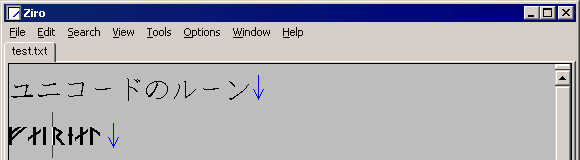
Unicodeエディタを使えばルーンを直接編集もできる
7-Zip の .7z 書庫。無数にある「ZIPよりは高圧縮」な形式のひとつで、そのなかでも特に高圧縮というわけでもなく、積極的に使う必要性を感じなかったし、実際、ほとんど使ってなかった。が、どうした弾みか、ふしぎなことに、たまたま 7z 圧縮したら、そのファイルに限って GCA のさらに半分にちぢむという目覚ましい結果が出た。
7-zip も捨てたものじゃない。きゅうきょ再検証してみた。
ふだん通りにファイルを配布していた――
2002.01.07 爆裂!ゆにこ~ど(850KB)。ブラックジャック見てるとき何となく手が暇だったので65536個のますめがある馬鹿でかい表を作ってみました(with PHP)。1ページですが、約1MBあります。巨大なテーブルのため回線が高速でもブラウザ自身のレンダリング処理に時間がかかることがあります。圧縮版: ZIP(174KB)、BZ2(110KB)、GCA(100KB)。
ところが、その次の日、説明できないふしぎないきさつから、なにげなく上のファイルを .7z圧縮してみた。酔狂なら、szip なり zzip なり書庫は星の数ほどあろうに、なんで 今さら 7-zip なんかにしたのか、うまく説明できないが、とにかく、ふとした弾みでしてみた。そうしたら43KBになってしまったのだ。そのときのメモ:
2002.01.08 7-zipを見直した。
すごい経験しました――下に書いた850KBの表、ZIP、BZ2、GCA、ごらんの通りの圧縮――これは「今回はGCAの勝ちか」というくらいで(手元で扱うファイルだと .bz2 がGCAに勝つことのほうが多い)べつだん不審な点は無いのですが、偶然というか、なんというか、ふだんそんなことしないのに、7-ZIP で圧縮してみたら。42.9KB――GCAのさらに半分以下という超高圧縮。なにこれ?何かの間違いでは?びびりました。こんなこともあるんですね~。たまたま同じパターンの繰り返しの多い表が 7z の圧縮アルゴリズムと相性バッチシだったのか。平均すると、7z って、ZIPよりは確かにすごいという程度でそんなにパッとしないと思ってたが(いまどきZIPより高圧縮というのは大前提なので)、こんな底力があったのね。
7-ZIPってこれまでは一応、持ってるってだけで、べつにマークしてなかったけど、LGPLのフリーソフトです。興味あるかたは、試してみてください(自分でも、もうちょっと調べてみます)。解凍しないでも書庫内が見れて一時的に開くこともできますが同様の .rar .ace .sit なんかみたいに「エクスプローラ」が大げさでないのが、いい感じ(GPL=商用でない=インターフェイスを派手にする必要なし、ってとこか)。気になる圧縮・解凍速度ですが、GCAより少し遅いかな、という程度で、充分、速いです。ここに物証のブツ(書庫)もアプしときます。unicode.7z(43KB)。圧縮に使ったのは手元にたまたまあった 7-ZIP Version 2.30 Beta 5 という去年の10月にダウンロードした古めのバージョン。解凍すると下の100~200KBの書庫と同じものが出る予定。
ちなみに、この表は、元をただせば1KBもない十数行のコードっす(JavaScriptで配れば確実にいちばん小さい)
驚いて、さっそく最新版(Version 2.30 Beta 9: 08-Jan-2002)をダウンロード、もう少しいろいろ試してみた(最新版といっても、上記と同じ 2.30 で Beta のうしろの数字が 5 から 9 になってただけだった。同じ1月8日、ほんの数時間前にリリースされたばかりのようだった)。
まずひとつメモとして、このアーカイバは黙って関連付けを奪うタイプだ。よくあることとは言え、関連付けを変えていいかどうかユーザに尋ねないのは、行儀が悪い。
関連付けは、てきとーに元に戻して、さっそく圧縮の比較を行った。150MB、136万行、という大きなログ(ASCIIテキストファイル)を縮めてみた。
| ファイル形式 | サイズ(KB) |
|---|---|
| Original | 153,735 |
| .bz2 | 7,622 |
| .GCA | 7,902 |
| .7z | 10,130 |
| .zip | 12,492 |
| .gz | 13,077 |
| .cab (mszip) | 13,126 |
パラメータは、だいたい圧縮率優先。結果は、ほぼ予想通りだった。bz2 と GCA が高圧縮、zip と gz が低圧縮(そのかわり高速)、そして 7z形式は zip よりは明らかに優秀だが、bz2 の敵でなく、書庫として積極的に使う必然性を感じない。.bz2 のほうがずっと高圧縮で、しかも世界中どこでもだいたい通用する一般的な形式だからだ。もっとも、150MBの圧縮ともなると、さすがに bz2 は遅いと感じた。cab よりは良いが……。cab は LZX ならかなり縮むと思うが、すご~~く時間がかかるのが分かってるので、mszip だけ試した。もっといろいろエントリーしている表が、2001年6月19日の記事にある。
単一ファイルでなく、いろいろ入ってる例として、1999年夏に公開されていた「Marybell Memories」のアーカイブでも実験してみた。テキスト、画像、midi など、ファイル数260、サブディレクトリ20、合計3,864KBのファイルセットだ。
| ファイル形式 | サイズ(KB) |
|---|---|
| Original | 3,864 |
| .rar | 2,367 |
| .GCA | 2,464 |
| .tar.bz2 | 2,513 |
| .tar.gz | 2,535 |
| .7z | 2,615 |
| .zip | 2,695 |
ここでも .7z は .zip よりはマシという程度にすぎない。これら2例が、ごくふつうのパターンだ。
けれど、「まぐれあたり」があると、.7z は GCA の半分にちぢんでしまうらしい。(いまいち謎)
| ファイル形式 | サイズ(KB) |
|---|---|
| Original | 849.88 |
| .7z | 42.90 |
| .GCA | 99.75 |
| .bz2 | 109.65 |
| .gz (7-Zip) | 119.38 |
| .gz (Lhaplus) | 173.08 |
| .zip | 173.80 |
この例では、gzip 圧縮でも、7-Zip を使うと一般的なアーカイバを使った場合より異様に高圧縮になった。
.7z は平均的にはパッとしないとしても、なにか未知数を秘めているようだ。説明書には 7z has open architecture, so it can support any new compression methods.
と意味深長なことが書いてある。ソリッド書庫でヘッダ圧縮をする、と書いてあるし、古典的なアルゴリズムと並んで bzip2 や PPMD の名もあがっている。TBytes、PBytes の超巨大ファイルを扱え、内部的にはファイル名をユニコードで保持するとも書かれている。近未来の世界標準を目指しているようだ。今後、優秀なアルゴリズムを実装すれば、GCA のライバルともなりうるし、ひょっとして GCA と統合されたりして……。そんなこんなで、いちおう注目しとこう。
7-Zip では、ZIP書庫などを「フォルダ」と同等に考える。Linux系のシェルで、ディレクトリとアーカイブを同じ色で表示するのがあるが、それと同じ発想だ。
ここで「7-Zip」というのは、書庫形式 .7z のことでなく、「7-Zip」というソフトのことなので混乱しないでほしい。
このツールは、その名の通り、zip, tar, gz, bz2, rar, cab, 7z の7形式を扱うことができる。対応形式の点では、rar が入っているのがやや特徴的だ――もちろん展開のみだが、ソリッド書庫を通常のアーカイブ同様、部分解凍できる。ライセンスの点では GNU GPLでなく、劣等GPLであり、なにやら寄金(?)もつのっている。
ソフトとしての特徴は、シェル統合と、シェルふうの書庫内ブラウジング。右クリックすると 7-Zip というメニューが現れる。サブメニューが3つ。Open(書庫をフォルダのように開く)、Extract files(すぐに解凍)、Add to Archive(圧縮)――
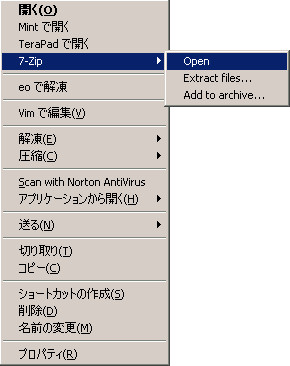
書庫ファイルのアイコンを右クリックした例
中ほどの「解凍」「圧縮」は、Lhaplusのメニューで 7-Zip とは関係ない。ちなみに Mint はフリーウェアの y_mint。
――このうち Open は「解凍せずにブラウズ」するもので、しかも書庫内を閲覧するインターフェイスにエクスプローラのコンポーネントを使っているので、「書庫」と「フォルダ」の違いをあまり意識せずに操作することも可能だ。
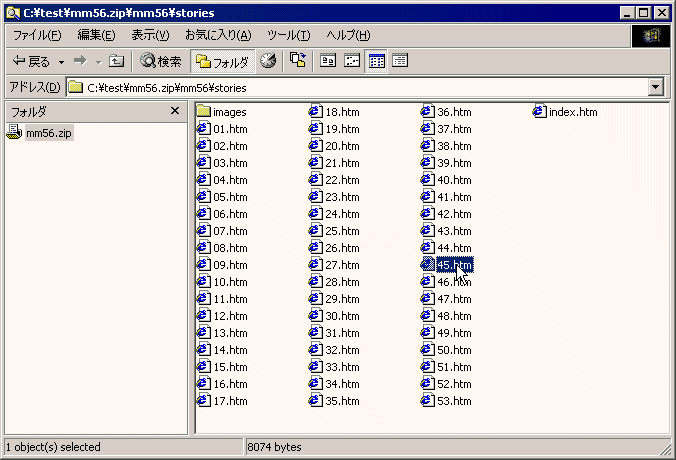
これで左のペインが樹形図の階層表示になれば最高だが……
上の図は、c:¥test フォルダにある mm56.zip のなかの mm56 フォルダのなかの stories フォルダをブラウズしている様子で、雰囲気的には「いっさい書庫を解凍することなく」書庫内のこのフォルダに含まれるファイルを自由に開いたり閉じたりできる。「書庫内」を意識せず「上へ」行ったり、さらにサブフォルダを開いたりできる。エクスプローラでふつうのフォルダを開いたのとほとんど同じだ。数千以上のファイルを含む巨大な書庫の場合、ディレクトリつき圧縮されている書庫のなかみが、このように(全体を解凍せずとも)階層的にブラウズできるのは、場合によって非常にべんりだ。
ZIPだけでなくRAR書庫に対しても、まったく同じようにできる(解凍レンジの手元のバージョンでは、rar は扱えない)。他方、.tar.gz などだと、なかみが「ひとつのtarファイル」にしか見えず、ふべんだ(解凍レンジなら、tar のなかみまで見える)。
.7z という独自形式の将来も少し楽しみだが、さしあたっては、WinRarのような書庫内閲覧ブラウザというのが、かなめかも。「エクスプローラの右クリックメニューから素早く呼び出せて、呼び出したインターフェイスもエクスプローラのまま」という透明性は、WinRar のインターフェイスよりすぐれている。しかも、WinRar と違ってフリーだ。ただし、エクスプローラのなかにいるように見えるだけで、実際には、アーカイバの内部で作業をしているので、書庫のなかにあるファイルの上でさらに右クリックした場合には、エクスプローラの見慣れたコンテクストメニューは出ない(WinRarでも同様)
これらの長所や制限を考えあわせたうえで「インストールしておいても損は無い」と思われるかたは、無料の小さなものなので、試しに使ってみると良いと思う。
ルーン文字は、北欧を中心に西ヨーロッパで用いられた文字で、独特のかくばった字形は、この文字が多く石や樹木に刻まれたことによる、とされる。中山星香の「はい!どうぞ」でエクタくんが雨をやませる呪文を唱えるシーンでは、ふきだしにルーン文字で「はやく天気になあれ」などと書かれている。また、真偽は不明だが、フィンランド語の「うた」という単語 runo が runes から派生したという説を聞いたことがある。(フィンランド語は、本来、ゲルマン語などの印欧語族と根本的に異なるウラル語だが、多くの語彙を印欧語から取り入れている)
ユニコードにおいてルーン文字は「新顔」、つまり、Unicode Standard 2.x の時代になかったが、3.0 でユニコード表に加えられた文字の例で、U+16A0 から 16FFに配置されている。
http://www.unicode.org/charts/PDF/U16A0.pdf
Microsoft が無料で配布している Windowsフォント「Arial Unicode MS」は現時点のバージョンで Unicode 2 のすべての文字を含んでいるが、ルーン文字を含まない(Version 2 の時点では、Unicode にルーン文字は含まれていなかった)。
なお、HTML 4.01 仕様書で参照されているのは、Unicode 3.0 であり、現在のバージョンは 3.1、策定中なのは Unicode 3.2 である。
Windows 2000 の通常の環境では、当然のことながら、ルーン文字を表示できない。ᚠ といった参照は、Mozilla であれ IE であれ、空白や疑問符などのゲタになる。ブラウザのフォント・マッチングの問題以前に、マッチさせようにも、そもそもシステムに利用可能なグリフがひとつもないからだ。
ルーン文字を使う従来的な方法として、「Wingdingsふう」、すなわちアスキー a, b, c, ... の位置にルーン文字の a, b, c, ... を置く方法がある(フェアノール文字、いわゆるトールキンの「エルフ文字」も、従来、この方法で利用されてきた)。Mac用のフォントには、この種のものが多い。Windows用のものとして、デンマーク製のフリーウェアBrynjolfson Rune Font(フォント名: Brynjolfson)がある。これをインストールしても、ユニコードとして参照することは、できない。
ユニコードとしてのルーンを含む Windows 用のフォントとして、ドイツのTITUS Cyberbit がある。このフォントをインストールしたところ、OSやブラウザを再起動することなく、単にページをリロードするだけで、ただちにルーン文字の表示が可能になった。MSIEでもMozillaでも、フォント名を明示する必要なく、ブラウザ側で利用可能なフォント(TITUS Cyberbit Basic)を勝手に使ってくれた。
TITUS Cyberbit Basic は、ルーン文字専用フォントでなく、汎用ユニコード補完フォントで、非常に多くの unicode range を含んでいる。
以下に実際の表示例を透過PNG画像で示す。IEとMozillaは、まったく同じレンダリングになるので、画像は一種類ずつになっている(どちらのブラウザでもこうなる)。
ᚠᛅᛁᚱᛂᛅᛚ<span style="font-family:Brynjolfson">faireal</span>参考までに、あなたのブラウザがこれらのコードをどうレンダリングするか試せるように、ここにコードを貼っておく。現時点では、ほとんどの場合、レンダリングに失敗するだろうが、それはブラウザのせいでなく、あなたのシステムに対応するフォントがないからだ。
ᚠᛅᛁᚱᛂᛅᛚ<span style="font-family:Brynjolfson">faireal</span>Brynjolfson フォントが存在しない場合――つまり、ほとんどすべての場合、第二の書き方だと、ふつうのラテン文字で faireal と表示されるだろう。このフォントは、システムにとっては、あくまで @font-face でインポートされるようなプライベートな「特殊なデザインのラテン文字」だ。他方、第一のコードのようにパブリックな標準ユニコードの文字番号を使ってルーン文字を参照したとき、HTML4.01準拠のブラウザであれば、レンダリングできないまでも、レンダリングできない文字であることを整然と表示することが望まれる(空白にするべきでない)。
すぐ下の「Mozilla/IE 多言語対応メモ」で観察された現象と異なり、font-family として Verdana などのルーン文字を含まないフォントを指定しても、ユニコードで参照した場合には IE はフォント・マッチングに成功する。
将来的には、すべての「完全」な環境において、定義されているすべてのユニコード文字(少なくとも基本プレインの約5万字)のそれぞれについて、少なくともひとつはグリフを実装することが望まれる(理論的に可能な 256×256=65536文字という数は、日本語環境で一般的に用いられるグリフの数を基準にすると、たいして多くない――おおざっぱにMS明朝+MSゴシックと同じ程度のファイルサイズで基本プレインにある世界の数万字を実装できてしまう)。携帯端末のような「不完全」な端末でも、「利用可能でない文字」は疑問符や空白と明確に区別されるべきであり、グリフが利用不可能であるときの機能の低下が整然としたものでなければならない。
Unicodeエディタを使えばルーンを直接編集もできる
「多言語対応モジラの逆襲」で、ユニコードを参照した場合の古典ギリシャ語の表示について、MSIE 6.0 と Mozilla 0.9.5 を比較した。MSIEは、実際にはシステム(OS)が利用可能なフォントのなかに表示すべき文字があるにもかかわらず、文字の表示に失敗することがある。Mozilla もある局面では同様の失敗をするが、現時点において、Mozilla は IE よりも正確に &#...;による参照をレンダリングできる。
IE も、このような「Mozilla なら表示できる文字」をまったく表示できないわけでは、ない。その文字が実際に含まれているフォント・セットを明示的に指定した場合で、かつ、そのフォント・セットがユーザのシステムに存在するなら、IE でも表示ができる。次の例を観察せよ。
<p>中国語では、ソフトウェアを <em lang="zh">软件</em> と言います。</p> <p>中国語では、ソフトウェアを <em lang="zh" style="font-family:'MS UI Gothic',serif">软件</em> と言います。</p>
软 に対応する文字を表示できるフォントセットがシステムにひとつでもインストールされていれば、Mozilla は、それを見つけてきて、うまく表示する。上の例のどちらもうまく行く。IEでは、どのフォントセットのなかを探すのか明示しないと機能しない。serif ないし sans-serif のような一般的な指定をしてもダメだ。上の例で第一のソースだとレンダリングに失敗し、第二のソースだと(MS UI Gothicが存在すれば)レンダリングに成功する。
「多言語対応モジラの逆襲」の例題では、古典ギリシャ語のフォントを Times New Roman, Times から探して、それでもなければ serif ということでUAが自分で適当に見つくろう……ということになっていた。IE は、このレンダリングになかば成功し、なかば失敗した。Times New Roman に含まれるギリシャ文字は表示できるが、Times New Roman のなかに該当する文字がなかった場合に、次の候補フォント内に探しに行かず、ただちに失敗を返すからだ。
手元の Windows 2000 では、古典ギリシャ語のフォントは、例えば、Palatino Linotype に含まれている。
したがって、次のように書くと(Palatino Linotypeがインストールされているシステムでは)MSIEとモジラが同じレンダリングを行う。
<div lang="grc" style="font-family:'Palatino Linotype',serif">...
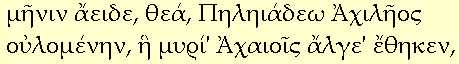
Mozilla 0.9.6 と MSIE 6.0 のどちらも P.Linotype にて表示
もし、Verdana, 'Palatino Linotype' と並べたらどうなるだろうか。Verdana にあるギリシャ文字は Verdana で表示され、ないものは第二候補の Palatino Linotype から借りてくることが予想される。Mozilla は実際にそのような動作をする。
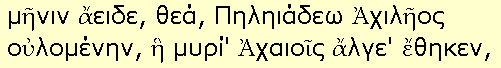
大半の文字は Verdana で、Verdana にない特殊文字は P.Linotype で表示
一方、IEは、Verdanaフォントがシステムに存在するのを確認した時点でフォントマッチングをやめてしまう。結果として、第二候補の Palatino Linotype まで探しにいけば全部の文字を表示できたのに、一部がゲタになってしまう。

これらの例では、Mozillaの動作のほうがすぐれている。Mozillaは、使用すべきフォント名を明示されなくても、そのユーザのシステムにあるフォントのなかから、その文字を表示できるフォントを自動的に捜索して、うまくレンダリングしてくれる。IEでほぼ同等の動作をさせるには、古典ギリシャ語の文字を含むフォント名を可能な限り列挙しなければならない(Palatino Linotype だけ書いても、このフォントがないシステムだってあるのだから)。もう少し抽象的に言えば、MSIEはCSS1の単純なフォント・マッチング・アルゴリズムの仕様に従っていない。
ただし、MSIE は(というより Windows OS の機能だろうが)もっと「インテリジェント」なマッチングを行う。例えば、Windows 2000 では、Tahoma という指示で ハングルもアラビア文字も表示できてしまうことが多い(Tahoma 自身には、もちろんハングルなど含まれていない)。ユニコード・エディタ等で「中国語はこのフォント、韓国語はこのフォント、フランス語はこのフォント……」と言語ごとにフォントを指定するのは面倒だが、Tahoma と言っておけば、あとはOSが面倒を見てくれる。これは Tahoma に対する「インテリジェント」なマッチングで、"MS ゴシック" などと指定してある場合は、この動作は起こらず、ハングルは全部ゲタになる。
MSIEのフォント選択にも、少しは利点がある。GulimChe といったハングルのフォント名を知らなくても、Verdana や Tahoma といった一般的なフォント名でハングルの部分も「周囲の Verdana と似た雰囲気のハングルのフォント」になったりする。Mozilla では、GulimChe なら GulimChe と書かないと、たぶんデフォルトの serif か何かになって、意図通りの雰囲気でなくなるかもしれない。――が、ウェブを書く側がフォントを明示的に指示できないのは、ふべんや不安のほうが大きい。「中途半端にインテリジェントなのでコントロールできなくて困る」というパターンだ。この問題に関するかぎり、Mozilla のほうが安心感があり、信頼できる。
ひとつだけ残念なのは、IEなら表示できる文書の題名(日本語、Latin以外)が Windows の日本語環境において、現時点の Mozilla では表示できないことだが、Mozilla正式版までには修正されるに違いない。
IE6.0 では、ギリシャ語拡張と日本語の相性が悪いようだ。Shift_JIS のような日本語のウェブページにギリシャ語拡張の文字を含めて、Arial Unicode MS というフォントを明示した場合、Arial Unicode MS は対応するグリフを持っているにもかかわらず、レンダリングに失敗する。同じ内容でも、UTF-8 や ユニコードで書けば、日本語とギリシャ語の両方が意図通りに表示される。
誤字を訂正した。Palatino Linotype というフォント名が、Paletino Linotype になってる場所があった。
ついでにこのフォントについて情報を足しておく。「Palatino フォント」は Hermann Zapf教授が1950年にデザインした英字系のフォントで、世界で最も広く使われた活字のひとつ。この「Palatino」に多数の新しい文字を追加するとともに、特にコンピュータ用としてモニタで読みやすいように字形を調整した新商品が、Palatino Linotype だ。旧「Palatino フォント」に追加されたのはギリシャ文字(アクセント記号つきも含む)とキリル文字など。Windows 2000 には、この有料フォントが含まれている。