
ユニコード番号U+20000台はSIPと呼ばれ、漢字「拡張B」数万文字が収録されています。 この最新領域の文字を、現在のブラウザで表示できるか試してみました。
関連記事「CJK拡張B上のJIS第3~第4水準の漢字303コードポイント」もごらんください。
当初のユニコードは U+0000 から U+FFFF までの16進4桁(2進16桁=16ビット=2バイト)、65536コードポイントを使っていましたが、6万程度のコード番号では世界の古今東西の文字記号を収録しきれず、Unicode 3.0 以降、U+10000以上にも文字が割り当てられてます。0x10000ごとの区切りをプレインといいます。
00000~0FFFF の区間は基本多言語プレイン(BMP)
10000~1FFFF の区間は補足多言語プレイン(SMP)
20000~2FFFF の区間は補足漢字プレイン(SIP)
となってます。プレイン0、プレイン1、プレイン2です。プレイン2はほとんどまるごと漢字(CJK Unified Ideographs Extension B、以下 Ext B と略)で、これまで未収録だった漢字が何万文字も入ってますので、U+0000~U+FFFF の範囲に入ってない人名用漢字や異字体などで、将来、日本語圏でもいろいろとお世話になるかもしれません。
ユニコードでいまいちばん楽しいのは何と言っても世界のいろんな文字が宝石箱のようにぎっしり実装されているBMPですが、 SMPも少しずつ文字が登録され楽しくなってきました。SMPの話題は別記事「基本多言語面を越えて: 古代イタリア文字」もごらんください。今回はSMPよりさらに上――といっても漢字なのでむしろ身近――なSIPを扱ってみます。
例題として、次のHTMLを取り上げます。
「
<dl> <dt>倭人在帶方東南</dt> <dd>倭人諸国が在るのは帶方の東南、</dd> <dt>大海之中</dt> <dd>大海のなか、</dd> <dt>依山嶌爲國邑</dt> <dd>山や島によって国境をなし、</dd> <dt>舊百餘國</dt> <dd>古く百以上の国があり、</dd> <dt>漢時有朝見者</dt> <dd>漢時代に我が朝廷を訪れ皇帝に謁見した者もあります。</dd> <dt>今使譯所通三十國</dt> <dd>現在、国交があるのは三十国。</dd> <dt>從郡至倭</dt> <dd>郡から倭へ至るには、</dd> <dt>循海岸水行歷韓國</dt> <dd>海岸沿いを水路、韓国をへて、</dd> <dt>乍南乍東</dt> <dd>沿岸を南へ東へ</dd> <dt>至其北岸狗邪韓國七千餘里</dt> <dd>半島の北岸、狗邪韓國まで七千里あまり、</dd> <dt>始度一海千餘里</dt> <dd>ここで初めて沖に出て一千里あまり、</dd> <dt>至對海國</dt> <dd>対馬国に至ります。</dd> <dt>其大官曰��狗</dt> <dd>そこの大臣はヒコという名で、</dd> <dt>副曰𤰞奴母離</dt> <dd>副大臣はヒナモリといいます。</dd> </dl>
このサンプルの注目点として、ひとつには、SJISになく CJK Unified Ideographs (U+4E00~U+9FFF) に入っている U+6B77 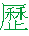 が出ます。歴の異字体で厂 (がんだれ)のなかの木木が禾禾になってるヤツ。
しかし、これは従来のJIS/SJIS/EUCにないといっても基本言語面中のしかも拡張でない基本漢字領域の文字なので、
いまどきのブラウザは、IE、Mozilla、Operaどれでも問題なく表示可能(フォントさえあれば)。
過去のブラウザ Netscape 4 でさえ表示できるほど。(もっともフリーのエディタのなかには、
UTF-8対応とか言いながら、この種の文字を扱えないものもあるようです。)
が出ます。歴の異字体で厂 (がんだれ)のなかの木木が禾禾になってるヤツ。
しかし、これは従来のJIS/SJIS/EUCにないといっても基本言語面中のしかも拡張でない基本漢字領域の文字なので、
いまどきのブラウザは、IE、Mozilla、Operaどれでも問題なく表示可能(フォントさえあれば)。
過去のブラウザ Netscape 4 でさえ表示できるほど。(もっともフリーのエディタのなかには、
UTF-8対応とか言いながら、この種の文字を扱えないものもあるようです。)
それはともかく、問題はプレイン2の U+24C1E  。これは卑の頭の点をとったような字です。
ここの文字が U+24C1E なのかハッキリしないのですが、U+20000台を使ってみたいのでそういうことにしときます。
でもって、これをウェブページに書くには、ふつうに考えると
。これは卑の頭の点をとったような字です。
ここの文字が U+24C1E なのかハッキリしないのですが、U+20000台を使ってみたいのでそういうことにしときます。
でもって、これをウェブページに書くには、ふつうに考えると
𤰞
ですが、surrogate pair を使うと U+D853 U+DC1E なので
��
という書き方も考えられます。(HTMLの仕様書では、まだこの書き方は言及されていない。MozillaもIEも、
この方法を知っている。)
上のサンプルでは、この文字が2回でるので、サロゲート・ペアを使う書き方と、
16進5桁での参照の両方を試してます。
Mozilla は実際にはサロゲートによる文字参照を解釈できるが、 XML ではこれを不正とみなす。 下記のデモでは、該当箇所で両方ともサロゲートを使わないように変更した。
結論からいうと、現在 Windows 2000 上のブラウザでは、Mozilla だけがSIPの文字を正しく扱えました(Mozilla 1.4a)。 Mozillaは、サロゲートで書いても5桁数値でも書いてもOK。 IE6 SP1 や Opera 7.10 beta 1 ではダメ。ただし、IE6は「ユーザ定義」言語を使うことによってSMPの文字を表示できるので、U+FFFF超の文字がぜんぜんダメなわけでもサロゲートがまったく使えないというわけでもなく、 プレイン1は何とかなる。が、今回のプレイン2は、言語設定をいじくったり、レジストリまで書き換えてみたものの、 Windows 2000 + IEでは表示成功しませんでした。一方、Mozilla は何もしなくて、ふつうにプレイン2の文字が表示できたのでびっくり。それどころか、モジラはプレイン2の文字を数値参照でなく、 直接ソースにタイプしてもOK。さらにモジラのコンポーザはプレイン2の文字をふつうに編集できてしまいます。 やってくれますね。……ただ、IEではOKなターナ文字の書式方向がモジラではひっくり返しになる、とかもあるので、 現状、一長一短というのがフェアな見方でしょう。
以下にソースを実際に貼っておきますが、CJK Extension B を表示できるフォントがないと、
いくらモジラでも U+24C1E は表示できません。
2003年4月現在、CJK Ext B を含んでいる Windows フォントは、
SimSun (Founder Extended)(ファイル名 SURSONG.TTF)だけです。
通常版のSimSunやSimSun-18030には含まれません。
SimSun (Founder Extended)は、Office XP Professional をインストールして、
さらに Office XP Proofing Tools をインストールすると追加されます。
なお、SimSun (Founder Extended) は中国語中心のフォントで、
39.6MB というものすごいサイズにもかかわらず、BMP領域の多言語サポートはしてません。
BMPにある Unicode 2.1 の全グリフを含む Arial Unicode MS が22.2MBなのを思えば、
中国の文字サポートがいかに大変か感じられます。
Ext B にあって SimSun (Founder Extended) にない文字が若干あります。 例えば、U+25771 にある 禾(のぎへん)に予 という字が、Ver. 1 には含まれてません。
上の例で嶌という字(島の異字体)がありますが、 原文では、本当は「山の下に鳥」でなく「山の上に鳥」になってます。 この異字体は、ユニコード3.2の範囲には未収録。
何万文字もの漢字が Ext B に追加され「それでもまだ足らない」とも言われてますが、コードポイントに文字を登録するだけでなく、使いたい文字をすばやく探せることも重要です。 ちょっと試せばすぐ実感できることですが、あちこちの領域に分散されて格納されている何万もの漢字を、 ひとつひとつ目で見ながら手動で探すのは非現実な話です。 大規模な拡張が行われたとき、「新しい文字」に対するフリーなフォントが必要なのと同じくらい、 新しい領域をもカバーした、フリーでべんりな検索手段が必要です。
SimSun (Founder Extended)(ファイル名 SURSONG.TTF)はパッケージソフトの付属品ですが(といっても Office なので、特殊なソフトではなく、そこらじゅうにあるソフトですが)、 SimSun-18030 は無料でダウンロードできます。 SimSun-18030 は Unicode 3.1 で追加されたぼうだいな Ext B(プレイン2の漢字)こそ含まないものの、 Unicode 3.0 で追加されたプレイン0内の Ext A (U+3400~U+4DB5)の漢字・約6500字をすべて含んでいるので、 リソースに余裕があればインストールしておくと良いでしょう。 シェアウェアのフォントCode 2000でさえ、Ext A は10分の1の650字程度しか含んでいないので、 Ext A を網羅するSimSun-18030 が無料というのは、けっこうありがたい話では。
ほしいかたは Microsoft のサイトの GB18030 Support Package (简体中文版)へ。インストールがうまく行かないときは、 ロケールとシステム言語を「中国語(中国)」に変更してからインストールし、あとから言語設定を戻してみる。
