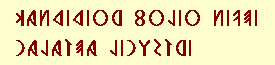
従来のUnicode規格になかったU+10000以上の文字に挑戦。Operaが善戦
ユニコード・ファンのみなさん、こんにちは。アラビア語、韓国語などではIEの独走でしたが、古代ギリシャ語勝負で Mozilla が逆襲、そして前回のルーン文字勝負では完全に互角でした。そして今回は――発音記号勝負をやると前から予告してましたが、ちょっと気が変わって、もっとおもしろい未開の荒野「プレイン1」で戦ってみたいと思います。
Unicode(って何?)には世界中のぼうだいな文字や記号が登録される予定ですが、現在一般的に広く用いられ始めているのは、そのうち初めの65536文字、すなわち「プレイン0」(第ゼロ平面)の約6万字です。基本多言語面(BMP)と言われるものです。6万文字種といえばアルファベット26文字の世界で考えれば巨大ですが、漢字をご存知のかたなら、大漢和辞典のようなものをちょっと思い浮かべれば「6万字で足りるのか?」と思うでしょう。BMPには漢字だけでなく世界中の文字が入るので、実際に漢字に割り当てられるコードポイントは6万よりずっと少なくなります。それでは不足でしょう。
実際のユニコードは、もちろん6万字で終わるわけでなく、そのあと、「プレイン1」「プレイン2」「プレイン3」……とそれぞれ一面あたり最大(理論値)65536文字が乗った「文字平面」が鬼のようにぞくぞく続くことになってます。ウェブページの規格でもCSS2はユニコードを16進6桁で書けるようになっていますから、理論上は第FF面のFFFF番の文字まで、十進法で言えば、第255面まで256×65536=1677万7216のコードポイントを書けます。(現時点の実際の規格では上限はもっと低い。)
発音記号だのギリシャ、アラビア、ヘブライ、サンスクリットだのの「ふつう」の文字は(日常生活で「ふつう」に使うわけでないにしても、とにかくそういう文字があることをふつうに知ってはいるような文字は)、どれも基本言語面、第0面に乗ってます。(というか基本言語面にも、あまり聞いたこともないような文字もけっこういろいろ乗っています。カナダの先住民族の言語を書き記す文字とかがそうです。)これら65536コードポイントについては、だいぶ前に一覧表も作りました。そして、この範囲では、現在(2002年2月)IEとMozillaが一長一短でほぼ互角であることも経験で分かってます。発音記号をちゃんと出せるか?は実用性もあっておもしろいし、いずれ取り上げるとしても、やっぱり65536番より上の未知の領域に、もっと強く
これまでフリーで使えるフォントがなくて実装を検証できずにいたのですが、次のページでフォントの試験バージョンを発見。
Code2001, a Plane 1 Unicode-based Font
Code2000 というフォントはシェアウェアなのですが、こっちの Code2001 はフリーウェア。Macでも使えるフォントだそうです。詳しくは上のページを見てください。基本言語面を越える higher plains のフォントを含んでいて試しがいがあります。主に Plain 1 ――通称 補足多言語面(SMP)――の文字。正式な日本語訳は知りませんが「補助多言語面」とも訳されています。特定の単言語でなく、いろんな言語の文字が汎用的につめこまれてる多言語なプレイン。なお、すでにお気づきのように、ゼロから数え始めるので、Plain 1 は面の番号は1ですが2番めの文字コード領域ということになります。SMPの利用予定の詳細については、次のページを見てください。
Roadmap to the SMP
基本多言語面のコードポイントをHTMLで文字参照する場合、16進数を使うと、
�   ... 
のように「&#x+16進4桁」で書けます。これに対して「より高い面」を参照すると、16進で5桁以上の領域に入ります。例えば、古代イタリア文字で「faireal」と綴ると、
𐌚𐌀𐌉𐌓𐌉𐌀𐌋
もちろんユニコードの区点番号も U+1031A のように U+FFFF より上の5桁になるわけです。
現在のユニコード規格(Ver.3.1)で、Plain 1 のいちばん最初にあるのが、この Old Italic です。番号で言うと、U+10300 から U+1032F の 48文字で、仕様書は次の場所にあります。
http://www.unicode.org/charts/PDF/U10300.pdf
ちなみに、U+10000以降のSMPのトップバッターは、エーゲ海文明に関連する文字が予定されており、有名な線文字BやAもこの領域に入る見通しです。
http://www.evertype.com/standards/iso10646/pdf/aegean.pdf
余談ですが、近い将来、ユニコードの時代になって、こうしたいろいろな文字を同じ文書の同じ行中に混在させて平坦に扱うようになった場合、最低でも1文字あたり20~24ピクセル角くらいの文字解像度が期待されます。それより低い画素数では、画数の多い難しい漢字などで字が潰れてしまうからです。これは「文字の物理的な大きさ」の話ではなく(物理的な大きさは画素の大きさしだいでデバイス依存)文字品質の話です。高品位の文字を指定すると文字が大きく見えすぎるとしたら、デバイスの画素密度が低いせいです。例えば1cmあたり千や万を越える物理画素があって、それをベースにした論理画素で文字サイズを適宜、切り替えられるなら、非常に鮮明な文字を利用することができるでしょう。
Old Italic は紀元前にイタリア半島で使われていた文字で、とくにはエトルリア語の碑文に用いられたものです。エトルリア語は非印欧語族と考えられ、エトルリア文明はギリシャ・ローマ文明にかき消されてしまった謎の文明のひとつ。エトルリア語に限らず、広い範囲、広い時代にわたって、いろいろな言語を書き表すのに用いられたいろいろな文字を、ひとまとめにオールド・イタリックとくくっていますが、実装では、同じコードポイントでも、言語属性によって、実際の
古代イタリア半島の古文例を探すのが面倒なので、とりあえずラテン語で試してみました。「アーキスとガラテーア」のラテン語対訳で使った一行め Candidior folio nivei Galatea ligustri「リグストルムの輝く葉より、もっとまばゆいガラテーア」ですが、このさい意味はどうでもよく、文字を表示できるかです。Unicodeの文字参照(ここでは十進法)を使うと、次のようなコードになります。65536より上の「高い領域」であることが一目瞭然です。
後述するように、「厳密」なW3C仕様では、このようなBMP外の領域を&記法で参照することはできないようですが、それはそれとして、現実のブラウザでどうなるか試してみましょう。
で、上のフォントをインストールして試してみたところ、Mozilla 0.9.8 と Opera 6.02 beta では、それぞれ一応の表示ができました。Mozilla では均等割付を指定したり、文字を右から左にレンダリングさせようとすると、まったく表示ができなくなります。また、Opera は右から左という指示を単に無視します。Mozilla や Opera の対応状況は完全とは言えません。が、IEだとまったく表示できませんでした(IE6 SP1 beta)。それに比べれば、Mozilla と Opera は、はるかに良く、これらでは、フォントさえ用意してやれば、BMP外のユニコードも参照できることが分かります。特に、この課題では、Opera が最上でした。以下の画像は、Opera 6.02 beta による表示例。
Windows 2000 では、このフォントに対して「フォントの縁を滑らかにする」も可能でした(上の画像では滑らかにしていません)。また、ユニコード・エディタの Ziro でも、この「超FFFF領域」の文字を扱うことができました。このように、Windows はOS自体として Higher Plains をサポートしているにもかかわらず、OSと一体化しているはずのIEで当該文字を処理できませんでした。文字コードをUTF-8やUTF-16にしたり、明示的にSurrogatesを有効にするようにレジストリにキーを追加したりもしましたが、ダメ。MSIEでは「&#x+16進5桁以上」の参照が未実装でしょうか。
基本多言語面(つまり最初の65536文字: U+0000 から U+FFFF)の外に最初に文字が割り当てられたのは、Unicode のバージョン3.1においてです。この3.1は2001年3月に公開されたもので、現時点(2002年2月)の最新正式バージョンです。まだできてから一年も経っていない新しい規格なので、全般的にアプリケーション側の実装の不備は仕方ないところです。とくにIE6は2001年6月以前にベータ公開されてるので、2001年3月下旬の仕様追加が反映されてないとしてもまぁ仕方ないのですが……。いずれにせよ、この領域のユニコードについては、実際に利用できるフォントもほとんどなく、まだ実用段階とは言いがたいです。現実的に、SMPの文字参照を実装していないのをIE6の「不備」と言えるのかどうか、よく分かりません。しかし実体としてUTF-8で書いてもレンダリングできないのは、どう考えてもIEの問題でしょう。
HTML4.01の仕様書には区点FFFFまでの例しか出ませんが、この仕様書は1999年のもので、当時はBMP外の文字の規格が定まっていなかったことに注意。HTML4.01ではISO 10646の文字番号を参照できることになってて、しかも参考文献欄の注記として、This reference also includes future publications of other parts of 10646 (i.e., other than Part 1) that define characters in planes 1-16.
と明示されてます(この範囲では、ISO 10646とユニコードは同じ)。これはUTF-8などで実体として使う話で、&記法で参照できるのは正式にはBMPだけのようですが、この点、W3Cの仕様が古いのであって、できるだけ早く拡張・改訂されるべきでしょう。仕様書を立てればSMPを数値で参照できてしまうOperaやMozillaのほうが「間違ってる」けど、実質的には仕様書が古い。すでに触れたようにCSS2では16進6桁で文字を数値参照できると明示されてます。
ご自分のブラウザでこのコードがどうレンダリングされるか確認するには、デモページをご利用ください。最新の Opera や Mozilla を使っていても、使えるフォントがインストールされていなければレンダリングできません。

SMPよりさらに上のSIP