下に走り書きしたスクリプトだけじゃ何の話か分かりにくいので、もうちょっとちゃんと説明します。
ウェブページでリンクを張るとき、リンクになってる部分がテキストじゃなくてイメージ(ボタン、バナー、ロゴなどと言われるもの)ってことは、よくあります。多くの場合、イメージ全体がクリッカブルで、どこをクリックしてもリンク先に飛びますが、ときどき同じ一枚のイメージでもクリックする場所によって飛ぶ場所などの働きが変わるヤツがあります。 企業のホームページのメニューなんかでよく見るイメージマップないしクリッカブル・マップと言われるヤツです。例えば日本列島の地図の北海道をクリックすると北海道の天気予報、本州をクリックすると……みたいなのとか。
つまり以下の話は主に画像を表示するブラウザに関係しています。(画像を表示しない環境でイメージマップがどうなるかは、また別の問題)
次の画像は「妖精現実」と書いてあるロゴで、ロゴのなかの「妖精現実」という文字が、ふつうのクリッカブル・テキストのように下線つきの青い字になってます(この文字は文字データでなく画像の一部です)。べつにこの青い字の上じゃなくてもイメージのどこをクリックしても「妖精現実」に飛ぶようにふつうにリンクを張ることもできますし、マップを使えば、この字をクリックしたときだけリンクになるようにすることもできます。下の画像は、どこをクリックしてもリンクというパターン。
青い下線つき文字を活かして、あたかもその文字がクリッカブルであるかのように、画像の文字部分以外をクリックしても反応しないようにすることもできます。これもよく使われるパターンでしょう。こちらのデモで実際に試せます。で、デモページを見たら詳しく書いてありますが、そういう動作を実現するには、img要素にusemap属性を指定します。
<img src="/image/faireal_logo.gif" alt="「妖精現実」のロゴ" width="80" height="50" usemap="#mymap">
usemap属性の属性値(上の例では #mymap)は、その画像に適用するマップリソースのURIでした。上の例では、同じページ内のmymapというアンカーというか名前がついたマップを参照してます。早い話、同じページのどこかに次のようなmap要素(これ自体は表示されない)を書いておけば良いだけ。
<map name="mymap"> <area coords="14, 7, 66, 20" href="http://www.faireal.net/" alt="「妖精現実」へのリンク"> </map>
マップを使う場合には、このようにマップの側でひとつひとつのarea要素ごとにalt属性を指定します。この例はエリアを一個しか定義してませんが一般には同じイメージマップにクリッカブルエリアがいっぱいあるので、画像側で指定できるひとつのaltだけじゃテキスト系や音声系のブラウザでリンクの識別ができないからです。それはともかく、usemap属性の値はURIだったのでマップはページ外でも良かったわけです(longdesc属性と同じ)。多くのページで共通のナビゲーションバーに同一のイメージマップを使うようなときのinclude処理を見越した話だったのでしょう。
XHTML1.0まではそうだったのですが、XHTML1.1ではusemap属性の値がID参照に変更されました。
同じページにあるマップを参照するならたいして差はないようにも思えます。実際、map要素については XHTML1.0以前のものを name属性→id属性という一般的変更だけでそのまま流用できます。が、img要素のusemap属性の側では、マップをURIとして(現実には同一ページ内のアンカーの形で)参照していたときは、当然、#をつけて呼び出していたのに、ID参照だったらこの#は不要になります――不要というより、あっては、ならなくなります。要するに、上の例だったら、次のように書き換えるわけです。
<img src="/image/faireal_logo.gif" alt="「妖精現実」のロゴ" width="80" height="50" usemap="mymap" />
前の例との違いは、usemap属性値の頭の#がなくなったこと。map要素自体は本質的に変わっていないけれど、img要素からそのmap要素を参照する方法が根本的に変更されたわけです。新しい属性値は #mymap でなく#のつかない mymap 。知らないと気づきにくいXHTML1.1 と 1.0 の非互換性のひとつでしょう。1.0やHTML4のマップそのままで1.1に移行するとパーサがエラーを出すってこと。
といっても、現時点では、この新しい仕様で動くブラウザはないみたいです。手元にあるWindows版のモジラ、Opera、IEなどは未対応。MSIEの場合、仕様には反するけれど、XHTML1.1でありながらmap要素のid属性をURIとして参照すれば(つまりusemap属性の頭に#をつけておけば)、ちゃんと動作して、mapのaccesskey属性まで生きます。
IE6は、マップをあたかもアンカーのように#mymapで参照して、そこにリンクすればそれなりにジャンプできます。ジャンプに関しては現時点では Mozilla も同様の動作をします。
もう少し仕様や実装が安定するまでのあいだ、暫定的に次のようにすることも考えられます。すなわち、データベースのテキストを読み込んだとき、もしusemap属性の頭に#がついていたら、xhtml1.1では仕様に合わせて#をとる。ただしクライアントがMSIEなら仕様を無視して#を放置。さらに、入力側でusemap属性に#がついていなくても、クライアントがIEならスクリプト的に#を補完して送る。
以上のトリッキーな処理についてメモしたのが、この走り書きです:
2002.02.17 xml→xhtml1.0/1.1バイリンガル書き中メモ。
仕様書通りに書くと現状、動くUAがひとつもないimg要素のusemap属性v.1.1。v.1.0では %URI で他のページにあっても良かったが、1.1では同一ページ内限定のIDREFになってた‥‥仕様書のChanges from XHTML 1.0 Strictを見るとたいして差がない印象なのですが、「変更点」として明示されてなくても、じつは色々変わってるし。
// map識別子、入力データ新旧どっちでもつじつま合わせ if($xhtml==11) { // IEはURIで書くと動く。accesskey属性まで完璧だから仕様書は無視 if($ua=="MSIE6"||$ua=="MSIE5") { $line = ereg_replace( "(usemap=\")([^#])", "\\1#\\2", $line ); } else { // mozilla/operaはどっちにしろ動かない。仕様書通りにしとく $line = ereg_replace( "usemap=\"\#", "usemap=\"", $line ); } }厳密に言うと、昔のマップはname="#name"つまりurl##nameでも行けたので上の判別法は理論的には完璧でない。人に使わせる実装なら、属性()=()属性値の()の位置の空白類は、すべての変換に先立ちまとめて除去しておく。
モジラはhtml4で書いてもマップのアクセスキーをサポートしないし。
この処理は公開(勧告)されてる新標準に一部、反してます。現状、誰も実装していないusemap属性の新様式が、XHTML2.0でどうなるのかも今の段階では断言できません。XHTML1.0以前のマップは(たとえstrictに書いてあっても)そのままではXHTML1.1で動作しませんが、クリッカブルマップは外部から参照されるものでないので、内部的に仕様変更になってもたいして実害があるわけでもありません。コストさえ惜しまなければ、ウェブの管理者がバージョンごとにちょっと書き換えるだけです(もしUAが対応できるなら)。name属性の廃止一般について言えば、もしname属性からid属性に全面変更するなら一般には外部からリソースを参照する「アンカー名」を変えなければならないので、自分のサーバ内での変更だけでは済まされない範囲に影響が及びます(idとしては使えないnameをアンカーとして既に外部からリンクされてる場合)。
イメージマップに関するかぎり、要するに、一般的なUAのなかにXHTML1.1仕様にまじめに対応してるものは(少なくとも今は)無いわけで、さしあたってはXHTML1.0で書いておくか、イメージマップは使わない、というのが現実的なソリューションでしょう。
以下のページには、仕様書通りに書くとどうなるか、各バージョンでのデモを用意しました。あなたのブラウザは、どのバージョンまでサポートしてるでしょうか?
このメモでは、日本語に対する CSS の text-align: justify; が実効的とは言えない Mozilla や Opera について、なぜ実効的でないかの原理を説明するとともに、サーバサイドの処理によって、これらのブラウザでも強制的に均等割付を行う方法を示します。このメモには別記事の追記があります。あわせてごらんください。
まず、次の画像をごらんください。これは MSIE のレンダリングで、日本語を美しく均等割付しています。

次は Mozilla の場合。上と見比べると、差がよく分かるでしょう。パラグラフの右端がぎざぎざして見栄えが悪い。全般的には良いUAであるモジラですが、均等割付を指定してるのにこのレンダリングは、ちょっと‥‥。

そこで、後述するアルゴリズムを適用すると――

――モジラでも、いちおう均等割付ができるようになりました。しかし文字間ピッチが固定されているためIEほど美しくない。アルゴリズム的な興味は別として、一般には、ぜひとも実装しようと思うほどのものじゃありません。大きいウィンドウでもっと広い範囲をみると、この割付方法もある意味スッキリしており、右端がぎざぎざがたがたの情けないレンダリングよりは良く見える点があります。
ローカル環境で、HTML/XHTMLを生成するサーバサイドXMLパーサに、モジラをフォローする変換を実験的に入れてみました。Mozilla 0.9.8+, Opera 6.01 en build 1041, Opera 6.01beta ja build 1039 で動作確認。
読み込んだ行を一行ずつ変換するライブラリに次のようなアルゴリズムを足します。これはPHP3国際化版の例ですがPHP4や他言語でも考え方は同じです。ただし、PHP4では多バイト文字まわりの関数仕様がまだ安定していません。以下のコードは、PHP3国際化版なら安定的に使用可能ですが、PHP4との互換性は、ありません。
if( $ua=="Mozilla" || $ua=="Opera" ) {
$line = mbereg_replace( "(、|。|」)", "\\1 ", $line );
$line = mbereg_replace( "(「)", " \\1", $line );
}
「\\1」の前または後ろに半角スペースを入れています。(と書きましたが、タブ文字 \t のほうが良いです。詳しくは後述。)注意点として、多バイト文字対応の正規表現関数を使っています。でないと、予期せぬ位置(前のダブルバイト文字の後半バイトと直後のダブルバイト文字の前半バイト)にマッチしていわゆるダブルバイト文字の分断が起き、最悪パーサが暴走します。
なぜ空白類を挿入することで均等割付が実現できるのでしょうか?
……どうやら、現在の Mozilla と Opera は均等割付するのにいつでも単語の切れ目で配分する動作のようです。分かち書きする言語(西欧語や韓国語)では、単語と単語のあいだのスペースを認識してうまくいくのですが、日本語のように分かち書きしない言語だと、明示的に入れた空白類の前までを長いひとつの単語だと認識してしまい、均等割付が実効的でないです。(最初期のモジラは、英語などの分かち書きする言語ですら均等割付できなかったので、それに比べればマシになってきています。)
そこで、上のようにして、データベースの文章をブラウザに送る前に細工し、いくつかの句読記号の前または後に空白を挿入、そこでワードラップしてかまわないことをモジラたちに教えてあげます。自分で切れ目を判断しないブラウザに「ここが単語の切れ目だからね!」と手取り足取り教えてあげるわけです。かわりに幅なしスペースや改行文字を挿入しても原理的には同じことですが、モジラは幅なしスペースなんてしゃれたものを認識しないし、改行文字は別の問題を発生させます。次の例を見れば、察しがつくでしょう。
パーサがどのレベルで置換を行うか?を注意することで(または正規表現を工夫することで)この問題を回避できるなら改行文字でも良いのですが、まあ半角スペースにしておくのがぶなんでしょう。概念上、<wbr> を挿入してる、といったほうが分かりやすいかもしれません。本当は、もっと徹底的にやれますが、禁則文字の扱いが面倒です。例えば、なんたらかんたら、まる、括弧閉じ、の、「まる」と「括弧閉じ」のあいだで改行できてしまうと、通常の禁則処理に反する結果になるでしょう。
ヒント: ソースに空白類(改行文字も含む)を挿入することと、ブラウザウィンドウの表示上で改行されることは別問題。ソースの空白類は、ブラウザに対して、均等割付のためにそこで表示上改行しても良いという「可能」(してもいい)を保証するもので、表示上の改行の「要求」(しなきゃならない)じゃない。
すでに触れたように、現在のモジラでは文字間が均等配分されないので、いわゆる(文字の)均等割付じゃなく単語の均等割付であって、どうもいまいちですが、とりあえず、こういうこともやればできる、という話です。Windows上のMSIE5、MSIE6の場合、さすがにOSを作ってる会社の製品だけあって、日本語をきれいに均等割付できます。IEはルビも使えるし。
逆に考えると、改行が禁則にならない位置すべてに空白類を入れてしまえば、モジラやオペラでもきれいに均等割付ができるでしょう。上の正規表現で「読点や句点の直前以外のすべての多バイト文字」をマッチさせてしまえば良いわけです。しかし、これだと転送されるテキスト量が2倍近くに増えてしまうし、モジラでソースを見ると1文字ごとに空白類が入って読みにくい、といった悪い副作用が出ます。とりわけ、UAが空白類をまったく無視せず1つまたは2つ以上連続する空白類について、表示上、空白ちょうどひとつをレンダリングする仕様だと、意図せぬ結果になってしまいます。
文字レベルで均等割付するMSIEの動作は、要素のletter-spacing属性値をユーザに無断で変更するという点で「悪しきインテリジェント」の一例だと思われるかもしれませんが、この属性の初期値について仕様上、明示的に認められている動作です(This value allows the user agent to alter the space between characters in order to justify text.
)。実効性に疑問があるモジラやオペラのやり方も、標準に反すると言うわけでなく、実装上の問題です。ここで問題にしているのはプラクティカルなことで、形式的に仕様に合致してるかしてないか?ということを議論してるわけじゃありませんが、形式的には3種類のUAともそれぞれそれなりに均等割付をサポートしてはいるわけです。
話を実務に戻して、本当にこのような処理を行うなら、処理されるテキスト内で処理対象となる句読記号を参照するには(句読点として「用いる」のでなくそのものを参照する場合)、実体を書かず、参照したほうが安全です。自分で定義するか、XML自体の文字参照を使えます。
どちらでも危険はないと感じるかもしれませんが、例えば、かぎかっこ文字を処理するスクリプトを <pre> のなかで引用しているとき、パーサが勝手な空白類を加えたら表示が乱れるばかりか、引用されているスクリプトの内容(たとえば置換文字列)が変更されてしまい、それを信じた読者はわけの分からないエラーで悩むかもしれません。また、なにかの弾みで、認証に関係するスクリプト(例: 掲示板の編集モード)がこのモジュールで処理されると、ハンドルが「ヤンキー娘。」とかのユーザは何度試しても「パスワードかユーザ名が違う」と言われて困惑するでしょう。変換されると困る文字に配慮しないと、そのモジュールを知らずに読み込んだとき(例えば掲示板の表示でも均等割付をしたいと考えた場合)、思いも寄らぬ副作用が起きるものです。
空白類の挿入について追加します。Operaの場合、改行文字、タブ文字を挿入するなら上の通りですが、半角スペースを挿入しても無視されます。Mozillaの場合、改行文字、タブ文字、半角スペースどれも同じ結果になります。改行文字の挿入には既に書いたような重大な危険があり、半角スペースはオペラで無効であることから、タブ文字を挿入するのが最善の選択でしょう。
均等割付については、CSS3で詳細に規格化される見通しです。CSS3 module: text, W3C Working Draft 17 May 2001 の Text alignment and justification をごらんください。ここで示されている text-justify属性(text-align属性の属性値text-justifyではない)は、MSIE5以降が独自にサポートしてきたものです。
「Mozilla, Opera でも日本語を均等割付」では、PHP3の多バイト対応正規表現を使った。このメモでは、多バイト対応が中途であるPHP4.0.xで同じことを実現する方法を述べるとともに、さらに美しい効果が得られるアルゴリズムも説明する
2002.02.16 IE6の標準準拠モードがらみのメモ: 2001年6月の「IE6 CSS Tips」や2001年8月の「Internet Explorer 6 リリース」でも触れましたが、MSIE6には「後方互換モード」と「標準準拠モード」があって、HTML文書の最初の行にDTDを書くと(もちろんDTDを示すURIのことです、以下同じ)「標準準拠」になります。細かいことは色々あるでしょうが、このサイト的にいちばん問題になるのは、テーブルの左右の余白を auto にすることでテーブルをセンタリングするという手。標準準拠モードにしておけば簡単にできることで、IE6ベータの時点からそれでやってきてました。ところが――
いろいろあって、x2xというしくみを試験導入しました。黙ってテストしてましたがすでにトップページとarticles/4/xx/の合計約25ページは、これに置き換わっています。どのページでも、?xhtml=11 をつけて呼ぶと有効なxhtml1.1形式、?xhtml=10 をつけて呼ぶと有効なxhtml1.0形式を返すようになってます(通常は環境によって自動切り替え&両方に対応できる新しいブラウザで見るぶんには、ソースの細部が違うだけで表示上は違いなし)。もちろんソースのソースは同じ。同じソースのソースからHTML4.01なソースを生成することも容易ですし、相手がモジラとかならクライアントサイドでxmlから変換させるというのもアリだろうし最終的にどうするかまだ考え中……それはいいとして、問題は、上記のMSIE6の「標準準拠」とのかねあい。
もしxmlベースにして、今のeuc-jpで通すと、xmlとしては1行めにxml宣言を書くことが必須でした。が、上に書いたように、msie6は1行めがdtdでないと標準準拠モードにならず、autoというキーワードが無効になってふべん。
だから、プラクティカルには、IEを認識したら、xml宣言はしないで文書タイプの行から出力すればいいわけです。IEはxhtmlの場合、それでOK。単なるxml(HTTPヘッダがつくとは限らない)と違ってxhtmlではレスポンスヘッダでエンコーディングを教えているので、文書内でエンコーディングを明示しなくてもコーディングは分かるわけです。
仕様書にはSuch a declaration is required when the character encoding of the document is other than the default UTF-8 or UTF-16.
とキッパリ書いてあったから仕様には反するがべつにいいと思ってたのですが、なんか、ぼんやり見てたら、仕様書が改訂予定になってて、その予定原稿を見たら、上の部分が Such a declaration is required when the character encoding of the document is other than the default UTF-8 or UTF-16 and no encoding was determined by a higher-level protocol.
になってるじゃないっすか。つわけで、仕様上も宣言を書かなくてOKになるので(「必須」から単なる「激しくお勧め」に変わる)、結局、サーバサイドで動的にxmlを変換するかたは、ie6に対しては当面xml宣言を入れないのが良いでしょう。もちろんieが変なモード切替をやめてくれれば(とりあえずdtdが2行目でも動いてくれれば)いちばん良いのですが、それは自分のコントロールできる事柄じゃないので。
なお「HTMLのソース」を書くのでなく、「ソースのソース」と「ソースのソースからHTMLのソースを生成するサーバ側スクリプトのソース」を書く、というコンセプトについては、昨年9月の「HTMLページの構造の
念のためにさらにくだいて説明すると、同一ページにつき、異なったバージョンやいろんなブラウザ専用のバージョンなど数ページを用意するんじゃなく(そんな面倒なことできない)、それらのベースになるデータだけを(一般には複数のファイルに分散して)用意しておき、その場その場で相手のブラウザにとってベストと思われるコードを動的に生成する、という意味です。これは少しも珍しいことでなく、サーバサイド処理のひとつの典型。
この方法にも微妙な問題点があります。例えば、モジラを認識したときモジラ専用のスタイルを送ったとして、それを見た事情を知らないモジラユーザが「このスタイルはモジラ専用だから好ましくないですよ」などと誤解するってことです(実際にはモジラを検出したからこそモジラ専用のスタイルを送った)。モジラに限らず、ネスケ4、オペラ、ieといった主なブラウザの最新バージョンのどれに対しても、最適化コードを動的にインポートしてるわけですが、環境変数を偽装してる相手だとわやになるっていう問題も。サーバ側で小細工せずともブラウザ側で標準準拠するのが本来ですが、そんなこと言っても現時点では
現在のIE6では、XML宣言とDOCTYPE宣言を同じ第一行に書いたとしても、標準準拠モードになりません。DTDのURLを第一行に書くかどうか、というより、正確に言うと、第一行めでもほかの何よりも先に書いてあるかどうか、を見ているようです。文章の最初がDOCTYPE宣言でなければDOCTYPE宣言なしと判断しているのかもしれません。
暴れん坊Windows:
http://www.geocities.co.jp/SiliconValley-SanJose/8700/K/7/24n0.htm
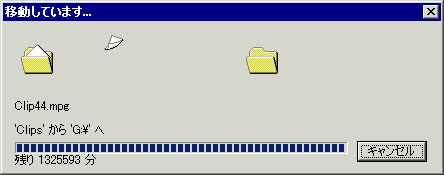
「残酷なWindowsのテーゼ」つながりというか。おもしろ。Win2Kは、ここまですごくないが「約2年かかるファイルコピー」のヤツは、win2000でも出たことあり(下の画像)。たった48時間くらい起動してるだけで時々変になるし(注: 48時間以上パソコンを操作しつづけてるという意味ではない。外出や寝てるときも電源を入れたままにしてると、ということ)。
ぼくの名まえは名無したん♪ あってもなくてもどうでもいいよぅな名無したん。
 「日本も寒いですね! 突然ですが・・ 2月18日のニュースステーションで12分の特集が組まれます。急なニュースが入った場合は水曜になります。僕自身の恥ずかしい姿が映るかと思いますが(泣き顔)見てやってください。」
「日本も寒いですね! 突然ですが・・ 2月18日のニュースステーションで12分の特集が組まれます。急なニュースが入った場合は水曜になります。僕自身の恥ずかしい姿が映るかと思いますが(泣き顔)見てやってください。」
数日前にそんなメールが写真家の久保田 弘信さんから届いてました。見れる地域のかたは、興味あったら見てみてください。追記: 放送日が2002年2月21日、木曜日に変更になったそうです。
それはそうと、そこにサムネイルを作っておいた「若いデモ隊」の写真ですが(2001年12月撮影)、久保田さんから届いたJpegは82.9KB、これをJPG Cleanerにかけたら、73.7KB。約10KBも縮んだ!という。解説記事に書いたように、この無料ツールは、画質には、まったく影響を与えてません。画像データは1バイトもいじらないです。「プロバの5MBのウェブスペースをぎりぎりまで使ってると思ったが、ただJPG Cleanerをまわしただけで500KB以上も空きが増えた! 魔法みたい」なんて感謝のおたよりも。つか、お礼はスロバキアの作者さんにどーぞ。情報がなければ存在しないのと同じかもしれないにしても。特にアドビのユーザだと効果が劇的なようです。
クリックして見れる写真は、もちろんゴミヘッダを削除した小さいサイズのほうのバージョンになってます。
ちなみに「プログレッシブJpeg」を選択すれば、これまた画質は同じままで3~10KB程度のサイズ軽減になり、しかもプログレッシブに従うブラウザならウェブでの表示も体感上は早くなります(最初に粗い画質でぱっととりあえず出て、だんだんじわじわと細部が表示されるパターン。体感的には待ち時間が減るがもちろんホントは逆にトータル処理時間が長くなる)。プログレッシブでの保存は最初に保存するときに指定するのが良いです。非プログレッシブのJpegを開いて単純にプログレッシブで保存しなおすと、再圧縮になってファイルサイズの割にムダに画質が落ちます。